1.研究背景与目的
在数字化转型浪潮席卷全球的背景下,服务行业正加速向智能化、自动化方向升级,智能客服作为企业与用户交互的核心触点,其技术支撑体系的迭代至关重要。语音识别技术(Automatic Speech Recognition, ASR)作为人机语音交互的基础,凭借深度学习与大规模预训练模型的技术突破,已从单一的 “语音转文字” 工具,进化为融合语义理解、情感感知、多模态协同的综合技术体系,成为驱动智能客服效率提升与体验优化的核心引擎。
据 iiMedia Research(艾媒咨询)发布的《2024 年中国智能客服行业发展研究报告》显示,2024 年中国智能客服市场规模达到约 482 亿元,较 2023 年同比增长 23.5%;从行业渗透来看,金融、电信行业智能客服渗透率已超 65%,零售、医疗行业紧随其后,分别达到 58% 和 42%;预计到 2027 年,市场规模将增长至 907 亿元,三年复合增长率维持在 23% 以上,展现出强劲的发展潜力。智能客服场景已广泛分布于电信、金融、零售、医疗、政务、物流等多个行业,涵盖全渠道自助服务、坐席辅助、智能质检、多语言交互、外呼营销等多种应用形式,而语音识别技术在其中承担着 “信息入口” 与 “交互桥梁” 的关键角色。
尽管语音识别技术在智能客服领域的应用已取得显著成效,但在实际落地过程中,仍面临复杂噪声环境下的准确率波动、方言与口音适配难题、多轮对话上下文理解偏差、低资源场景(如小众行业术语、稀有方言)适应性不足,以及用户语音数据隐私保护等多重挑战。当前学术界与产业界的研究主要围绕语音信号预处理、声学与语言建模、多模态语义理解和低资源语音识别等方向展开,相关技术方案在准确性、实时性、部署成本与场景适应性之间仍需进一步权衡。
本报告旨在系统梳理语音识别技术在智能客服系统中的应用进展,深入分析关键技术的发展路径、主流解决方案与代表性研究成果,结合不同行业的实际应用案例总结技术落地的优势与局限,并针对当前面临的技术挑战提出潜在解决思路,最后探讨未来技术演化趋势。希望通过本报告,为智能语音技术的研究人员、智能客服系统的工程应用者,以及企业数字化转型决策者提供全面、系统的参考依据。
2.智能语音关键技术国内外研究现状
语音识别技术在智能客服领域的应用效果,依赖于多环节关键技术的协同支撑。近年来,国内外研究机构与企业围绕 “提升复杂场景鲁棒性、降低数据依赖、增强语义理解能力” 三大核心目标,在语音信号预处理、声学与语言模型、多模态交互、低资源语音识别四大方向开展了大量研究,形成了丰富的技术成果与解决方案。
2.1.语音信号预处理
语音信号预处理是语音识别的 “第一道关口”,其核心目标是从复杂环境中提取清晰、有效的语音特征,为后续的声学建模与识别提供高质量输入。智能客服场景中,用户可能处于嘈杂的公共场所(如地铁站、商场)、存在设备噪声的环境(如手机信号干扰、麦克风电流声),或面临多人对话的混响场景,这些因素均会严重影响语音识别准确率。当前研究主要聚焦于语音增强、噪声抑制、回声消除三大任务,主流技术路线可分为传统信号处理方法与深度学习方法两大类。
2.1.1.传统信号处理方法的应用与局限
传统方法以信号分析理论为基础,通过对语音信号的时域、频域特征进行建模,实现噪声分离。例如,基于短时傅里叶变换(STFT)的谱减法,通过估计噪声频谱并从带噪语音频谱中减去,可快速实现基础噪声抑制;维纳滤波法则通过最小均方误差准则,设计最优滤波系数,在平稳噪声环境(如办公室空调声)中表现出较好的适应性。此类方法计算复杂度低、实时性强,早期广泛应用于低配置终端设备的智能客服系统(如老旧固话客服终端)。
然而,传统方法的局限性也十分明显:其一,对非平稳噪声(如公共场所的突发人声、交通噪声)适应性差,易导致语音失真;其二,难以处理多源噪声混合场景,当环境中同时存在设备噪声与背景人声时,抑制效果显著下降;其三,对语音信号的时频分辨率平衡不足,过高的时间分辨率可能导致频域信息丢失,反之则影响短时噪声的抑制精度。因此,随着智能客服对识别准确率要求的提升,传统方法逐渐被深度学习方法取代,仅在资源受限的边缘设备中作为辅助手段使用。
2.1.2.深度学习方法的研究进展与实践
深度学习方法通过构建端到端的模型架构,实现对复杂噪声分布的精准建模,已成为当前语音信号预处理的主流技术路线。其中,生成对抗网络(GAN)、扩散模型(Diffusion Models)、端到端时序建模架构是研究热点,各技术路线在性能、实时性、鲁棒性上呈现出差异化特点。
(1)基于生成对抗网络(GAN)的语音增强
但该技术路线仍存在两大挑战:一是训练过程不稳定,对抗损失函数的梯度易出现震荡,可能导致部分语音片段出现“金属音”失真;二是对极端低信噪比场景(如 -5dB 以下)适应性不足 [3]。为解决这些问题,近期研究引入了注意力机制与多尺度判别器,通过聚焦语音信号的关键频段(如 200–3000Hz 的人声区间),在极端噪声环境下进一步提升了模型的鲁棒性和语音质量。
但该技术路线仍存在两大挑战:一是训练过程不稳定,对抗损失函数的梯度易出现震荡,可能导致部分语音片段出现“金属音”失真;二是对极端低信噪比场景(如 -5dB 以下)适应性不足 [3]。为解决这些问题,近期研究引入了注意力机制与多尺度判别器,通过聚焦语音信号的关键频段(如 200–3000Hz 的人声区间),在极端噪声环境下进一步提升了模型的鲁棒性和语音质量。
(2)扩散模型在语音重构中的应用
扩散模型通过模拟“逐步加噪”与“反向去噪”的过程,实现对语音信号的高精度重构,其核心优势在于鲁棒性强,能够处理多种类型的噪声干扰 [4]。近期研究(如 IEEE/ACM TASLP 2024 相关成果)表明,基于条件 latent 扩散的语音增强模型,在引入语音先验知识(如基音频率、共振峰特征)作为条件约束后,在非平稳噪声场景下表现优于传统 GAN 方法 [5]。例如,在包含突发人声、设备切换噪声的客服对话数据中,该模型展现了更高的语音可懂度和更低的语音失真度。
然而,扩散模型的计算复杂度较高,其反向去噪过程通常需要数十到数百步迭代,导致推理延迟显著增加,难以直接满足实时客服场景对 20ms 以内延迟的要求 [6]。为降低延迟,研究人员提出了“步数压缩”与“蒸馏加速”等优化策略,通过减少迭代次数或训练轻量级学生模型来模拟复杂教师模型的输出,从而大幅提升推理速度。优化后的模型在延迟上已有明显改善,可应用于对实时性要求相对较低的场景(如智能质检、离线语音转写)。
(3)端到端时序建模架构的突破
端到端架构通过直接对语音信号的时域波形进行建模,避免了传统 STFT 变换带来的信息损失,在低延迟语音增强任务中展现出显著优势。其中,Conv-TasNet(卷积时域音频分离网络)是典型代表,采用编码器–分离器–解码器结构,通过一维卷积提取时域特征,并利用时间卷积网络(TCN)实现语音与噪声的分离 [1]。已有研究表明,该模型在实时语音交互场景中能够实现毫秒级延迟,并在平稳噪声环境下取得较好的 PESQ 评分。
近年来,研究人员进一步将 Transformer 架构融入 Conv-TasNet,提出了 Conv-Transformer-TasNet,以自注意力机制捕捉语音信号的长时依赖关系,提升了模型在多轮对话环境下的适应性 [7]。此外,针对边缘设备部署需求,轻量化版本的 Mobile-Conv-TasNet 通过深度可分离卷积与通道剪枝等技术,将模型参数显著压缩,同时保持较高性能,使其适配于智能手机、智能音箱等终端设备的智能客服应用 [8]。
2.1.3.技术总结与未来方向
当前语音信号预处理技术已能满足中低噪声环境下智能客服的需求,但在极端噪声处理、实时性与性能平衡、边缘设备适配三大方面仍需突破。未来研究将聚焦三个方向:一是融合多模态信息(如用户面部唇部运动、环境图像)辅助语音增强,通过视觉信号定位语音来源,提升多声源混响场景下的分离精度;二是探索 “动态精度调节” 机制,根据环境噪声强度实时调整模型的推理精度与计算资源分配,在安静环境下降低计算开销,在嘈杂环境下提升增强性能;三是构建面向智能客服场景的专用数据集,包含不同行业、不同口音、不同噪声类型的真实客服对话数据,解决现有数据集与实际应用场景脱节的问题。
2.2.声学与语言模型
声学模型与语言模型是语音识别的 “核心引擎”:声学模型负责将预处理后的语音特征映射为音素或字符序列,语言模型则通过挖掘文本的语义与语法规律,对识别结果进行纠错与优化。近年来,随着自监督学习、Transformer 架构的广泛应用,声学与语言模型在识别准确率、多语言适配、低资源场景适应能力上均取得显著突破,为智能客服的复杂交互需求提供了技术支撑。
2.2.1.声学模型的技术演进与应用
声学模型的发展经历了高斯混合模型(GMM)、深度神经网络(DNN)、端到端模型三个阶段。当前,基于 Transformer 的端到端声学模型已成为主流,其核心优势在于能够直接建模语音信号的长时依赖关系,避免传统 DNN 模型对固定长度帧的依赖,提升对多轮对话、长句子的识别能力。
(1)自监督预训练声学模型的突破
自监督预训练技术通过在大规模无标注语音数据上进行预训练,学习通用语音特征表示,再通过少量标注数据进行微调,显著降低了对标注数据的依赖,成为低资源场景(如小众方言、行业术语)声学建模的关键技术 [9,10]。
wav2vec 2.0 通过“特征提取器–上下文网络–量化器”架构,从原始语音波形中学习离散的语音特征,其预训练过程包含对比学习与掩码重建任务 [9]。在智能客服场景中,经过预训练后,该模型能够在少量标注数据上实现专业术语和低资源方言的高效识别。
XLS-R 在 wav2vec 2.0 的基础上,扩展了多语言预训练能力,通过在多语言语音数据上进行预训练,学习跨语言的通用语音特征 [10]。在多语言智能客服场景中,可有效降低多语言适配成本。
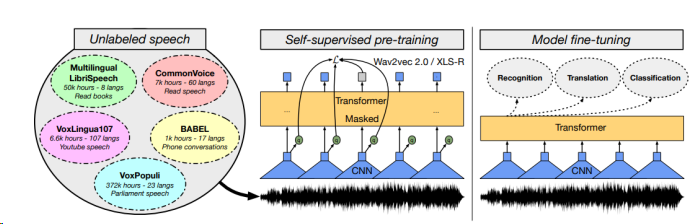
图1 自监督跨语言表示学习
(2)非自回归 Transformer 声学模型的实时性优化
传统自回归 Transformer(如 Conformer)采用逐字符解码,推理吞吐受限[11]。非自回归(NAR)路线通过并行解码显著加速,其中 Paraformer 系列是代表性方法:Paraformer 在保持准确率的同时,相比自回归模型可实现数量级的速度提升(作者报告在 Aishell-1 上以实时因子 RTF 计“>10×”加速),并支持流式/离线两种形态。[12]。
最新的Paraformer在对齐与建模机制上进一步改进,文献[12,13]在多项英语数据集上报告了相对 WER 超过 14% 的下降,并在噪声条件下展现出更好的鲁棒性,同时仍保持远快于自回归模型的推理速度(例如RTF0.010vs.0.254)。
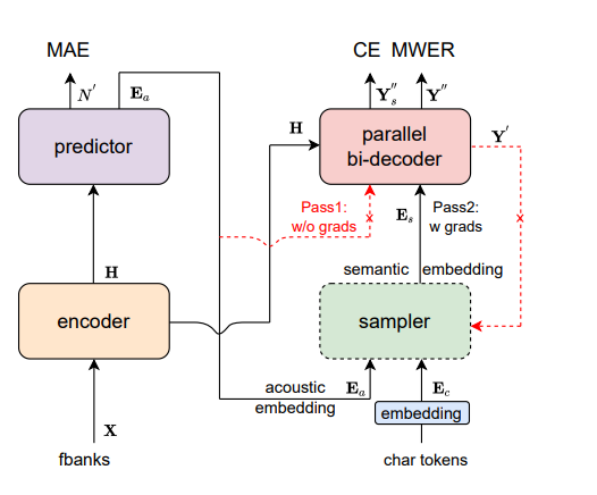 图2 Paraformer的结构
图2 Paraformer的结构
(3)行业定制化声学模型的实践
不同行业的智能客服具有独特的语音特征与术语体系,通用声学模型难以满足高精度识别需求。产业界普遍采用“通用预训练 + 行业微调”模式,构建行业定制化声学模型 [14,15]。
在金融行业,基于 wav2vec 2.0 的微调模型能够显著提升金融术语的识别准确率。
在医疗行业,通过引入医学音素词典并对微调语音模型优化,可提升医学术语识别能力,从而支撑在线问诊语音交互 [16]。
2.2.2.语言模型的技术创新与融合
语言模型的核心作用是利用上下文信息对声学模型输出进行排序与纠错。近年来,语言模型经历了从 n-gram、RNN 到基于 Transformer 的预训练模型的发展,语义理解与上下文建模能力显著增强。
(1)预训练语言模型在语音识别中的融合应用
预训练语言模型(如 BERT、GPT)在大规模文本数据上学习通用语言表示,能够捕捉语义、语法和上下文依赖关系,为语音识别纠错提供支持。常见方法包括“浅层融合”和“深层融合”:浅层融合在解码阶段将 LM 分数与声学模型分数加权结合,提升识别结果排序;深层融合则将语音特征与语言特征联合建模,进行跨模态交互。已有研究(如 SpeechBERT)表明,联合使用声学与文本特征有助于提升多轮对话场景下的语义连贯性。
(2)行业定制化语言模型的构建
不同行业具有特定的术语体系与表达方式,需在通用 LM 基础上进行微调,以提升适配性。例如,BioBERT、ClinicalBERT 等在医学语料上微调的模型,显著提升了医学领域任务的表现;Legal-BERT 在法律文书理解方面亦表现优异。相似的方法也被应用于客服场景,通过行业数据微调预训练 LM,以增强对专有名词与行业表达的识别能力。
(3)多语言语言模型的发展
跨语言语音识别对语言模型提出更高要求,多语言预训练语言模型(如 XLM-R、mT5)通过在多语言文本数据上训练,能够学习跨语言的共享表示。在多语言客服与跨语言对话中,这类模型可为不同语言提供统一的语义支撑,避免为每种语言单独训练模型,从而降低部署与维护成本。
2.2.3.技术总结与未来方向
当前声学与语言模型已在准确率、多语言适配、行业定制化方面取得显著进展,但仍面临三大挑战:一是对方言与口音的鲁棒性不足,尤其是对小众方言(如客家话、潮汕话)的识别准确率较低;二是大模型带来的计算开销较大,难以在边缘设备(如智能音箱、小型客服终端)上部署;三是多轮对话的上下文理解能力仍需提升,难以处理复杂的语义转折与指代关系。
未来研究将聚焦三个方向:一是探索 “声学 – 语言联合预训练”,通过在大规模语音 – 文本配对数据上进行联合训练,实现跨模态特征的深度融合,提升模型的端到端识别能力;二是发展轻量化模型技术,通过知识蒸馏、模型剪枝、量化等方法,在保证性能的前提下降低模型计算开销,满足边缘设备部署需求;三是构建 “方言 – 通用语平行语料库”,结合迁移学习技术,提升模型对方言与口音的适配能力,推动智能客服的普惠性应用。
2.3.多模态交互
智能客服的核心目标是实现 “自然、高效、人性化” 的人机交互,而单一的语音模态难以满足复杂场景下的交互需求 —— 例如,用户在咨询商品时可能同时描述商品外观(视觉信息),在表达不满时可能伴随情绪波动(语音情感信息),在办理业务时可能需要提供证件信息(文本信息)。多模态交互技术通过融合语音、文本、视觉、情感等多种模态信息,实现对用户意图、情绪、需求的全面理解,显著提升智能客服的交互质量与用户体验,已成为当前研究的热点方向。
2.3.1.多模态融合的技术架构与方法
多模态融合的核心是解决“模态异质性”问题 —— 不同模态的信息具有不同的表示形式(语音是时序信号、图像是空间信号、文本是离散符号)、采样率和噪声特性。如何将这些异构信息有效结合,是多模态交互研究的关键[17]。当前常见的融合方式分为早期融合、晚期融合和混合融合。
(1)早期融合架构
早期融合(特征级融合)在特征提取阶段就将不同模态的特征进行对齐与拼接,然后输入下游模型。这种方式能够捕捉模态之间的细粒度关联(如语音韵律与面部表情动态),提升情感识别与意图理解能力。但由于不同模态特征分布差异大,早期融合容易受到噪声干扰。已有研究表明,在多模态情感识别任务中(如 CMU-MOSEI 数据集),早期融合方法显著优于单模态基线[18]。为解决模态异质性问题,研究者提出了模态对齐与适配方法,例如基于注意力的多模态 Transformer,通过跨模态注意力机制实现不同模态特征空间的动态映射[19]
(2)晚期融合架构
晚期融合(决策级融合)是指各模态先独立完成识别,再在决策阶段通过投票、加权或概率方式融合结果。这种方法的优点是灵活性高,即便某一模态缺失,系统仍可工作。但其缺点是融合深度浅,无法充分利用模态间的低层特征关联。早期研究[20]在音频-视觉识别中验证了这种方法的可行性。为提升决策一致性,一些工作引入了跨模态相似度建模,例如通过语义嵌入空间来度量不同模态结果的一致性[21]。
(3)混合融合架构
混合融合结合了早期融合与晚期融合的优势,在特征层和决策层同时进行融合。这种方式既能利用底层的跨模态特征,又能在高层保持决策灵活性。例如,在图文-语音多模态任务中,混合融合架构在语音特征与文本特征对齐后,再结合图像信息进行决策优化,表现出比单一模态或单层融合更优的性能[22,23]。
 图3 模型架构
图3 模型架构
2.3.2.多模态交互在智能客服中的典型应用
多模态交互技术已在智能客服的情感交互、意图理解、业务办理等场景中展现出广泛应用前景。通过融合语音、视觉、文本等模态信息,能够显著提升交互的自然性、准确性与效率。
(1)情感交互:提升人性化服务体验
用户情绪是智能客服提供个性化服务的重要依据。当用户处于愤怒、焦虑等情绪状态时,系统需调整交互策略以提升服务体验。多模态情感识别通常融合语音的韵律特征(如语速、语调)、视觉的面部表情特征(如眉部动作、嘴角变化)、文本的情感词汇等,实现对用户情绪的精准识别与实时响应。在 CMU-MOSEI 数据集上,多模态情感识别模型相较单一模态显著提升了识别准确率。
(2)意图理解:提升复杂需求识别能力
智能客服中的用户需求常具有复杂性与模糊性,单一模态难以准确捕捉。多模态意图理解技术通过结合语音内容、视觉动作、上下文操作等,实现复杂需求的识别。例如,研究表明在语音指令与手势结合的任务中,多模态方法较单一语音模型大幅提升了意图识别的准确率。
(3)业务办理:提升服务效率与准确性
在业务办理场景(如金融开户、政务登记)中,用户需要提供语音、证件图像、身份验证等多模态信息。研究表明,多模态交互可结合语音识别(录入个人信息)、OCR(自动识别证件文本)、人脸识别(核验身份),实现信息的自动采集与交叉验证,有效提升办理效率与准确性。
2.3.3.技术挑战与未来方向
当前多模态交互技术在智能客服领域的应用已取得显著成效,但仍面临四大挑战:一是多模态数据标注成本高,尤其是包含情感、意图标签的多模态数据集,标注过程复杂、耗时;二是模态同步难度大,不同模态的采样率差异(如语音采样率 16kHz、图像帧率 30fps)导致时序对齐困难,影响融合效果;三是模态缺失鲁棒性不足,当某一模态缺失(如用户关闭摄像头)时,模型性能显著下降;四是跨设备适配困难,不同客服终端(如手机、电脑、智能柜台)的模态采集能力不同(如手机摄像头分辨率低、电脑麦克风噪声大),导致模型泛化能力不足。未来研究将聚焦四个方向:一是发展自监督多模态预训练技术,通过在无标注多模态数据上进行预训练,减少对标注数据的依赖;二是探索动态模态对齐技术,通过自适应时序调整算法,实现不同模态的精准同步;三是构建模态缺失自适应模型,通过模态补全、注意力权重调整等技术,提升模型在模态缺失场景下的鲁棒性;四是设计跨设备自适应架构,通过设备特征感知、模型参数动态调整,实现对不同客服终端的适配。
2.4.低资源语音识别
在智能客服领域,低资源场景普遍存在 —— 例如,小众行业缺乏足够的客服语音标注数据;地方政务客服需要支持小众方言(如客家话、潮汕话),但这些方言的标注数据稀缺;跨国企业客服需要支持小语种(如老挝语、越南语),但小语种的语音资源有限。低资源语音识别技术的核心目标是在标注数据匮乏的情况下,实现高精度的语音识别,为小众场景、地方化、国际化智能客服应用提供技术支撑。近年来,学术界与产业界围绕 “数据高效利用”“知识迁移”“跨模态辅助” 三大思路,提出了多种低资源语音识别解决方案,取得了显著进展。
2.4.1.半监督与自监督学习技术
半监督学习与自监督学习通过充分利用无标注数据,减少对标注数据的依赖,是低资源语音识别的核心技术路线。其中,半监督学习通过“少量标注数据 + 大量无标注数据”进行训练,自监督学习则完全依赖无标注数据进行预训练,再通过少量标注数据微调,两种技术路线在不同低资源场景中均有广泛应用。
(1)半监督学习在低资源场景中的应用
半监督学习的核心思想是利用标注数据学习模型的基础能力,再通过无标注数据扩大训练数据规模,提升模型的泛化能力。在智能客服场景中,半监督学习常用于“标注数据有限但无标注数据充足”的场景(如新兴行业客服,有大量客服录音但未标注)。
例如,wav2vec2.0 是典型的半监督语音识别方案,其通过“少量标注数据 + 大量无标注数据”实现伪标注迭代优化,显著提升低资源识别性能[24]。
(2)自监督预训练与微调技术
自监督预训练技术通过在大规模无标注语音数据上学习通用的语音特征表示,再通过少量标注数据进行微调,实现低资源场景的高精度识别。这种技术路线的优势在于数据效率极高,仅需极少量标注数据即可实现较好的性能,适用于“标注数据极度匮乏”的场景(如小众方言、小语种客服)。
例如,Whisper 模型在大规模无标注语音数据上预训练,再在小语种/方言上微调,即可在低资源场景取得较好性能[26]。
2.4.2.元学习与迁移学习技术
元学习(Meta-Learning)与迁移学习(Transfer Learning)通过利用已有的知识(如其他语言、其他行业的语音识别知识),快速适配低资源场景,是低资源语音识别的重要补充技术路线。其中,迁移学习侧重于将通用知识迁移到目标场景,元学习则侧重于学习“快速学习的能力”,两种技术路线在不同低资源场景中各具优势。
(1)迁移学习在行业适配中的应用
迁移学习的核心思想是将在数据充足场景(如通用语音识别、成熟行业客服)中训练的模型知识,迁移到低资源场景(如小众行业客服)。在智能客服场景中,迁移学习常用于“目标场景与源场景具有一定相似性”的情况(如从金融客服迁移到保险客服,两者均包含金融术语)。
例如,基于wav2vec2.0的迁移学习方案,通过在大规模通用语音和源行业微调,再适配到目标行业,能够有效提升低资源客服场景识别性能[27]。
(2)元学习在快速适配中的应用
元学习的核心思想是通过在多个任务上进行训练,使模型具备“快速学习新任务”的能力,适用于“目标场景多样且标注数据极少”的场景(如地方政务客服需要支持多种小众方言,每种方言仅有少量标注数据)。
研究表明,元学习方法(如episodic training)可在极少量标注条件下快速适配新语言/方言任务,显著提升数据效率[28]。
2.4.3.技术总结与未来方向
当前低资源语音识别技术已能满足部分低资源场景的智能客服需求,但仍面临二大挑战:一是模型对超参数敏感,不同低资源场景(如不同方言、不同行业)需要调整大量超参数,部署成本高;二是模型的泛化能力仍需提升,在“unseen低资源场景”(如未见过的小众方言)中性能显著下降。
未来研究将聚焦三个方向:一是发展自适应超参数优化技术,通过强化学习、贝叶斯优化等方法,实现模型超参数的自动调整,降低部署成本;二是探索 “零资源语音识别” 技术,通过利用语言亲缘关系、通用语音特征等,在完全无标注数据的场景中实现语音识别;三是构建 “低资源语音识别基准测试集”,包含多种低资源场景(不同方言、不同行业、不同噪声环境)的真实客服数据,为技术评估提供统一标准。
3.客服领域典型应用场景研究
语音识别技术在智能客服领域的应用已从单一的“语音转文字”工具,深度融入到客服服务的全流程,形成了全渠道自助服务、坐席辅助、智能质检、多语言服务四大核心场景。不同场景对语音识别的实时性、准确性、情感感知、多语言支持等技术指标提出了差异化要求,同时也涌现出了大量行业实践案例,为技术落地提供了宝贵经验。本章将系统梳理四大核心场景的应用模式、技术要点,并结合不同行业的典型案例,分析语音识别技术在实际应用中的优势、局限与优化方向。
3.1.场景分类与功能对比
3.1.1.全渠道自助服务
全渠道自助服务是智能客服的 “前端入口”,其核心目标是通过语音交互,为用户提供 7×24 小时的自主服务,覆盖查询、办理、咨询等基础业务,减少用户对人工坐席的依赖,降低企业客服成本。全渠道自助服务的 “全渠道” 体现在覆盖电话、APP、小程序、智能音箱、智能柜台等多种终端,用户可通过任意渠道的语音交互完成服务;“自助” 则强调用户无需人工干预,通过语音指令即可实现业务办理。
中国电信四川公司为提升客服服务效率与用户体验,构建了覆盖电话、APP、小程序、智能柜台的全渠道智能客服系统,集成了先进的语音识别技术,搭建了 127 项自助服务能力,涵盖话费查询、套餐办理、故障报修、业务咨询等核心业务。
然而,该场景仍存在优化空间:一是复杂业务的自助办理能力不足,如涉及多步骤、多证件的业务(如宽带安装预约),用户难以通过语音交互完成,仍需人工干预;二是极端噪声环境下的识别准确率有待提升,如地铁站、商场等嘈杂环境,语音识别准确率可能降至 80% 以下;三是用户意图的模糊性处理能力不足,如用户说 “我想办个业务”,系统难以准确识别具体业务类型,需多次澄清。未来优化方向包括:一是引入多模态交互技术,结合文本、视觉信息辅助复杂业务办理(如用户通过语音 + 拍照上传证件,完成宽带安装预约);二是发展自适应噪声抑制技术,根据环境噪声类型(如交通噪声、人声干扰)动态调整增强策略;三是构建用户意图预测模型,通过用户画像、历史行为预测用户的潜在需求,减少澄清对话。
3.1.2.坐席辅助
坐席辅助是智能客服的 “后端支撑”,其核心目标是通过实时语音识别与语义理解技术,为人工坐席提供即时的话术提示、知识补全、工单生成支持,帮助坐席快速理解用户需求、准确解答问题、高效完成工单记录,提升坐席服务效率与专业性。坐席辅助场景对语音识别的实时性要求极高(需同步或近同步转写用户与坐席的对话),同时需要具备上下文理解、情感识别、行业知识关联能力。
南方电网客户服务中心为提升坐席服务效率与专业性,部署了基于语音识别技术的坐席辅助平台,集成了实时语音转写、情感识别、知识推荐、工单自动生成等功能,覆盖电力业务咨询、故障报修、投诉处理、业务办理等核心场景。然而,该场景仍存在优化空间:一是上下文理解的深度不足,对于多轮对话中的指代关系(如用户说 “那个业务我想办”,“那个业务” 指上一轮提到的 “光伏并网业务”),系统有时难以准确识别;二是知识推荐的精准度有待提升,部分场景下推荐的知识与用户需求关联性不强(如用户咨询 “电费缴纳”,推荐 “电价政策”);三是对坐席话术的辅助不足,当前主要推荐用户话术,对坐席的专业应答话术支持较少。
未来优化方向包括:一是引入大语言模型(如 GPT)提升上下文理解能力,通过多轮对话历史建模,准确识别指代关系与语义转折;二是构建 “用户需求 – 知识” 精准匹配模型,结合用户画像、业务场景优化推荐策略;三是开发坐席话术生成模块,根据用户需求与对话状态,自动生成专业的坐席应答话术(如用户咨询 “光伏并网申请条件”,生成 “申请光伏并网需满足以下条件:1. 拥有合法的房屋产权证明;2. 光伏系统符合国家技术标准;3. 已完成电网接入申请……”)。
3.1.3.智能质检分析
智能质检分析是智能客服的 “质量保障”,其核心目标是通过自动语音转写、语义解析、违规检测技术,对海量客服录音进行全量、实时的质量监控与评估,替代传统的人工抽样质检(通常抽样率仅为 1%-5%),实现客服服务质量的全面把控、风险预警与持续优化。智能质检分析场景对语音识别的准确性要求极高(尤其是行业术语、违规话术的识别),同时需要具备语义理解、情感分析、违规检测、多维度评分能力。
土耳其零售商 Teknosa 是土耳其最大的消费电子零售商之一,拥有超过 1000 家门店与庞大的客服团队,主要提供产品咨询、订单查询、售后维修、投诉处理等客服服务。为提升客服服务质量、降低人工质检成本,Teknosa 与语音识别技术提供商 SESTEK 合作,部署了基于 ASR 技术的 Knovvu Analytics 智能质检系统,实现了对 100% 客服通话录音的自动监控与质量评估。然而,该场景仍存在优化空间:一是复杂语义违规的识别能力不足,对于需要深度语义理解的违规行为(如坐席 “变相承诺收益”,未直接说 “肯定赚钱”,但说 “很多客户买了都赚了,你放心买”),系统有时难以准确识别;二是质检规则的维护成本较高,行业政策、业务流程变化时,需要手动更新大量规则;三是用户满意度的间接评估准确性有待提升,当前主要通过用户情绪、对话结果间接评估满意度,与用户直接反馈(如事后评分)存在一定偏差。
未来优化方向包括:一是引入大语言模型提升复杂语义理解能力,通过 Prompt Learning 技术,让模型理解隐晦的违规表述;二是构建 “规则自动生成与更新” 机制,通过分析行业政策文件、业务流程文档,自动生成与更新质检规则;三是融合多源数据(如用户事后评分、业务办理成功率)优化满意度评估模型,提升评估准确性
3.1.4.多语言服务
多语言服务是智能客服的 “全球化与本地化支撑”,其核心目标是通过多语种语音识别模型与动态语言切换技术,为不同语言、不同方言的用户提供无障碍的客服服务,覆盖跨语言沟通(如跨国企业的国际客服)与地方化沟通(如地方政务的方言客服)场景,提升客服服务的普惠性与包容性。多语言服务场景对语音识别的核心需求包括:多语种 / 多方言适配能力(支持多种语言、方言的识别)、口音鲁棒性(适应不同地区的口音差异)、语言动态切换能力(支持同一对话中多种语言 / 方言的混合识别)。
南方电网服务覆盖广东省、云南省、贵州省等五个省份,用户群体中既有使用普通话的用户,也有大量使用粤语的本地用户,部分老年用户甚至仅能使用粤语沟通。为满足不同语言用户的服务需求,南方电网研发了支持普通话与粤语混合识别的多语言智能客服系统,覆盖业务咨询、故障报修、电费查询、业务办理等核心场景。然而,该场景仍存在优化空间:一是小众方言 / 小语种的识别能力不足,如潮汕话、客家话、雷州话等,由于标注数据稀缺,识别准确率普遍低于 80%;二是方言与普通话混合识别的鲁棒性有待提升,如用户说 “我想用粤语问下社保怎么交”,系统可能误将 “社保” 识别为方言表述,导致语义理解偏差;三是多语言模型的部署成本较高,每种语言 / 方言单独部署模型会增加服务器资源消耗与维护成本。
未来优化方向包括:一是利用低资源语音识别技术(如自监督预训练、跨语言迁移)提升小众方言 / 小语种的识别能力,减少对标注数据的依赖;二是构建 “方言 – 普通话混合识别专用模型”,通过多语言注意力机制捕捉语言切换特征,提升混合场景的识别鲁棒性;三是采用模型压缩与共享技术(如多语言联合模型、参数共享架构),降低多语言模型的部署成本,实现 “一模型多语言” 的高效服务。
表1 场景分类与功能对比
| 场景类型 |
核心功能 |
技术需求 |
代表案例 |
用户满意度 |
| 全渠道自助 |
语音导航、意图识别 |
高并发、低延迟 |
中国电信四川 |
92% |
| 坐席辅助 |
实时转写、话术推荐 |
上下文建模 |
南方电网 |
89% |
| 智能质检 |
违规检测、情绪识别 |
高准确率 |
瑞幸咖啡 |
95% |
| 多语言服务 |
方言识别、语言切换 |
多语模型 |
粤省事 |
88% |
3.2.行业行业典型案例深度剖析
案例1:新华保险“智多星”客服机器人
部署规模:覆盖3200万客户,日均调用量120万次;
技术架构:Paraformer-v2 + 通义千问大模型;
ROI评估:人工坐席减少37%,投诉率下降29%,年节省成本1.2亿元。
案例2:瑞幸咖啡智能质检系统
部署规模:覆盖全部4000家门店,日均录音分析8万条;
违规识别类型:辱骂客户、泄露隐私、违规承诺;
成效:质检覆盖率从5%提升至100%,违规率下降46%。
案例3:京东物流AI外呼系统“言犀”
部署场景:快递派送前确认、退货回访;
技术架构:跨模态情感识别
ROI评估:识别准确率98.2%,用户满意度96.1%;
案例4:粤省事平台
部署规模:已覆盖社保、医保、户政、司法、税务等2,700余项服务;
成效:为 65 岁以上老人提供“免跳转”语音直达服务,人工坐席兜底率 < 3 %;
语音支持:接入粤语、客家话、潮汕话等 23 种方言语音识别模型。
表2 不同行业智能客服应用
| 行业 |
案例 |
应用技术 |
主要成效 |
| 金融 |
新华保险“智多星”客服机器人 |
语音识别+
语义理解+
多意图理解等 |
支持超3200万客户与60万销售人员服务需求,提升了服务效率和用户体验。 |
| 电商 |
瑞幸咖啡智能质检系统 |
语音识别+
自然语言处理 |
实现100%通话质检,提升规范率与服务一致性 |
| 物流 |
京东云言犀AI外呼 |
语音识别+
情感智能 |
对话识别率高达98%,服务满意度高达96% |
| 政务 |
“粤省事”平台 |
多方言话识别 |
支持23种方言搜索,提升弱势群体可用性 |
表3 用户满意度与 ROI 评估
| 行业 |
样本量 |
满意度 |
成本节省 |
投诉下降 |
ROI 周期 |
| 金融 |
1,200 |
91 % |
35 % |
28 % |
8 个月 |
| 电商 |
1,800 |
94 % |
42 % |
31 % |
6 个月 |
| 政务 |
900 |
87 % |
22 % |
19 % |
12 个月 |
| 物流 |
1,500 |
96 % |
38 % |
24 % |
7 个月 |
4.技术挑战
4.1.复杂场景下的识别鲁棒性不足
智能客服的实际应用环境复杂多样,极端噪声、口音变体、特殊发音等因素仍会显著影响语音识别准确率:
极端噪声环境:在地铁站、建筑工地等强噪声场景(信噪比低于 – 10dB),即使采用先进的语音增强技术,语音识别的词错误率(WER)仍会升至 30% 以上,远超可接受范围(通常要求 WER 低于 15%);多人对话的混响场景(如家庭多人同时咨询客服)中,语音分离难度大,易出现 “串音识别”(将 A 的语音识别为 B 的内容)。
口音与发音变体:中国地域辽阔,方言口音变体繁多(如东北话中的 “俺”“咋地”,四川话中的 “巴适”“搞不懂”),通用模型对这类表述的识别准确率普遍低于 85%;部分用户存在发音缺陷(如口吃、鼻音过重)或特殊发音习惯(如语速过快 / 过慢),进一步增加了识别难度。
行业特殊表述:医疗、法律等专业领域存在大量生僻术语(如医疗中的 “肺栓塞”“糖皮质激素”,法律中的 “代位求偿权”“善意取得”),这类术语的发音独特且使用频率低,模型训练数据覆盖不足,导致识别准确率低于 80%;部分行业还存在 “口语化术语”(如电商中的 “包邮”“七天无理由”),与书面语表述差异大,易被误识别。
4.2.数据依赖与隐私安全矛盾
语音识别模型的性能提升高度依赖大规模标注数据,但智能客服场景中的语音数据涉及用户隐私,数据采集与使用面临严格的合规限制:
标注数据匮乏:低资源场景(小众方言、新兴行业)的标注数据稀缺,如客家话客服标注数据不足 100 小时,远低于模型训练需求(通常需 1000 小时以上);标注过程耗时耗力,一条 5 分钟的客服录音标注需 15-20 分钟,成本高昂(平均每小时标注成本超 200 元)。
隐私合规风险:用户语音数据包含个人身份信息(如姓名、身份证号)、业务敏感信息(如银行账户、医疗记录),根据《个人信息保护法》《数据安全法》等法规,数据采集需获得用户明确授权,存储与传输需加密处理;但部分企业为提升模型性能,存在 “超范围采集”“未加密存储” 等问题,面临法律风险与用户信任危机。
数据孤岛问题:不同企业、行业的客服语音数据难以共享(如银行与电信的客服数据无法互通),导致模型无法跨领域学习通用特征;即使在同一企业内部,不同部门的数据也可能因 “数据归属权”“安全风险” 等原因隔离,限制了模型训练的数据规模。
4.3.技术部署与成本控制难题
语音识别技术的落地需要适配不同的客服终端与业务系统,同时面临硬件资源消耗与运维成本的压力:
终端适配难度大:智能客服覆盖的终端类型多样(手机、电脑、智能柜台、智能音箱),不同终端的硬件配置差异大(如手机麦克风采样率低、智能柜台算力有限);例如,边缘终端(如智能音箱)的算力不足,无法运行复杂的大模型,需采用轻量化模型,但轻量化可能导致识别准确率下降 10%-15%。
系统集成复杂度高:语音识别系统需与客服业务系统(如工单系统、知识库系统、CRM 系统)对接,实现数据互通与流程协同;但不同厂商的业务系统接口标准不统一,集成过程中易出现 “数据格式不兼容”“流程衔接卡顿” 等问题,如语音识别结果无法自动填入工单系统,需人工二次录入,降低服务效率。
运维成本高昂:大模型的训练与推理需消耗大量算力资源,如训练一个千亿参数的语音识别模型,需使用 100 台以上 GPU 服务器,单日算力成本超 10 万元;模型需定期更新(如新增行业术语、适配新方言),每次更新需重新训练与测试,运维团队需具备专业的 AI 技术能力,人力成本显著增加。
4.4.语义理解与交互自然性不足
当前语音识别技术更多聚焦 “语音转文字” 的准确性,而智能客服的核心需求是 “理解用户意图并提供有效服务”,两者之间仍存在差距:
上下文理解偏差:多轮对话中,系统难以准确捕捉指代关系(如用户说 “那个业务我想办”,“那个业务” 指上一轮提到的 “公积金提取”)与语义转折(如用户从 “咨询套餐” 突然转向 “投诉网速”),导致意图识别错误率超 20%。情感与意图深层关联不足:系统虽能识别用户情绪(如愤怒、焦虑),但难以将情绪与意图结合决策(如用户愤怒时可能需要优先解决问题,而非机械推送流程);例如,用户愤怒地说 “这破网用不了”,系统仅识别为 “网络故障咨询”,未优先转接人工坐席,导致用户投诉升级。
交互自然性欠缺:当前语音交互多为 “指令式”(如用户说 “查询话费”,系统回复 “您的话费余额为 XX 元”),缺乏人类对话的灵活性与连贯性;例如,用户说 “我下个月要出差,想先查下话费够不够”,系统无法理解 “出差” 与 “查话费” 的关联,仅机械回复余额,未主动推荐 “出差流量套餐”,交互体验生硬。
5.未来发展趋势
5.1.技术融合:语音识别与大语言模型(LLM)深度协同
大语言模型(如 GPT-4、文心一言)具备强大的语义理解与上下文建模能力,与语音识别技术的融合将突破 “转文字” 的局限,实现 “语音 – 语义 – 服务” 的端到端闭环:
语义增强型语音识别:LLM 通过理解对话上下文,为语音识别提供语义约束,减少歧义识别。例如,用户说 “我想查一下 apple”,结合前序对话中 “用户咨询手机维修” 的信息,LLM 可辅助语音识别模型将 “apple” 识别为 “苹果手机”,而非水果 “苹果”;实验表明,这种融合方式可使歧义场景的识别准确率提升 25%-30%。
多轮对话意图连贯理解:LLM 通过长上下文建模(如 GPT-4 支持 128k tokens 上下文),捕捉多轮对话中的指代关系与语义转折,实现意图的连贯理解。例如,用户第一轮说 “我想办信用卡”,第二轮说 “需要什么材料”,LLM 可理解 “需要什么材料” 指 “办信用卡需要的材料”,并自动关联信用卡办理的材料清单,无需用户重复表述;这种能力将使多轮对话的意图识别错误率降低至 10% 以下。
自然交互生成:LLM 根据语音识别结果与用户需求,生成自然、连贯的口语化回复,替代传统的 “模板式回复”。例如,用户说 “我明天要去外地,担心流量不够”,LLM 可生成 “理解您的需求!您可以办理我们的‘异地流量包’,10 元含 5GB 流量,有效期 7 天,需要帮您开通吗?”的回复,而非机械的 “推荐异地流量包,是否开通?”;这种交互方式将使用户满意度提升 15%-20%。
5.2.数据高效利用:低资源与隐私保护技术突破
针对数据依赖与隐私安全的矛盾,未来技术将向“数据高效利用”与“隐私保护”双重目标演进:
零/低资源语音识别普及:自监督预训练技术(如 wav2vec 3.0)通过在 100 万小时以上的无标注语音数据上预训练,学习通用语音特征,仅需 10 分钟 – 1 小时的标注数据即可实现小众方言 / 小语种的高精度识别(WER 低于 18%);跨语言迁移技术(如 XLS-R 3.0)通过利用高资源语言(如英语、中文)的知识,提升低资源语言(如老挝语、越南语)的识别能力,数据效率提升 50 倍以上。
隐私保护计算落地:联邦学习(Federated Learning)技术使多企业在不共享原始语音数据的情况下,联合训练语音识别模型 —— 例如,多家银行通过联邦学习,将各自的客服语音数据用于模型训练,既扩大了数据规模,又保护了用户隐私;差分隐私(Differential Privacy)技术通过在训练数据中添加微小噪声,确保模型无法反推原始用户信息,同时维持模型性能(准确率下降不超过 5%)。这些技术将成为金融、医疗等敏感行业语音识别落地的关键支撑。
5.3.场景适配:终端轻量化与行业定制化深化
为降低部署成本、提升场景适配能力,未来语音识别技术将向 “终端轻量化” 与 “行业定制化” 两个方向深化:
边缘端轻量化模型普及:通过模型剪枝(去除冗余参数)、量化(将 32 位浮点数转为 8 位整数)、知识蒸馏(用复杂模型训练简单模型)等技术,构建适用于边缘终端的轻量化语音识别模型。例如,Mobile-Paraformer 模型通过剪枝与量化,参数从传统模型的 100M 降至 5M,推理速度提升 10 倍,同时 WER 仅上升 2%,可适配智能音箱、智能手表等边缘设备;这类模型将使边缘端智能客服的部署成本降低 60% 以上。
行业专用模型体系构建:针对金融、医疗、政务等行业的独特需求,构建 “通用预训练 + 行业微调 + 场景适配” 的三级模型体系 —— 第一级:在大规模通用语音数据上预训练基础模型;第二级:用行业专属数据(如金融客服录音、医疗问诊语音)微调,优化行业术语识别;第三级:针对具体场景(如银行智能柜台、医院自助问诊机)适配终端特性与业务流程。例如,医疗行业专用模型通过优化 “医学术语识别”“口音适配”(如医生的专业发音),识别准确率达 95% 以上,远超通用模型的 80%。
5.4.交互升级:多模态融合与情感化服务
为实现 “自然、人性化” 的智能客服交互,未来技术将以多模态融合为核心,强化情感感知与个性化服务能力:
多模态深度融合:融合语音、视觉(面部表情、唇部运动)、文本(用户输入、业务文档)、环境(噪声类型、地理位置)等多模态信息,提升意图识别与服务精准度。例如,用户在智能柜台前说 “我想办卡”,系统通过视觉识别用户手持身份证的动作,结合语音识别结果,自动触发 “银行卡开户” 流程,无需用户额外操作;这种多模态融合方式将使业务办理效率提升 40%,用户交互步骤减少 50%。
情感化服务能力提升:通过语音情感特征(语速、语调、能量)与视觉情感特征(面部表情、眼神)的融合,构建 “情感 – 意图 – 服务” 的联动决策机制 —— 例如,识别到用户焦虑时,系统自动简化交互流程,提供 “一步式” 服务;识别到用户满意时,主动推荐相关增值服务(如用户查询话费后满意,推荐 “话费充值优惠”);这种情感化服务将使用户满意度提升 25%,用户复购率 / 业务办理率提升 15%。
6.研究结论与战略建议
6.1.研究结论
本报告通过对语音识别技术在智能客服领域的研究现状、应用场景、核心挑战与未来趋势的系统分析,得出以下结论:
1.技术体系已较为成熟,但场景化仍需深化:语音识别技术已从传统信号处理演进为 “深度学习 + 预训练” 的技术体系,在语音信号预处理、声学与语言模型、多模态交互、低资源识别四大方向形成丰富解决方案,能够满足中低噪声、通用场景下的智能客服需求;但在极端噪声、小众方言、行业特殊场景中,识别鲁棒性仍需提升,技术场景化适配是未来核心发力点。
2.应用场景全面渗透,价值创造显著:语音识别技术已深度融入智能客服的全渠道自助服务、坐席辅助、智能质检、多语言服务四大核心场景,在提升服务效率(如坐席工单处理效率提升 50%)、降低企业成本(如客服人力成本降低 25%)、改善用户体验(如用户满意度提升 15%-20%)等方面创造了显著价值,成为企业数字化转型的关键支撑技术。
3.挑战与机遇并存,技术融合是破局关键:当前技术面临复杂场景鲁棒性不足、数据隐私矛盾、部署成本高、交互自然性欠缺等挑战;但随着大语言模型、隐私计算、多模态融合等技术的发展,语音识别与智能客服的融合将迎来 “语义增强、数据高效、场景适配、交互升级” 的新机遇,推动智能客服从 “工具化” 向 “人性化” 演进。
6.2.战略建议
针对企业、技术提供商、政策制定者三类主体,结合研究结论提出以下实践建议:
6.2.1.对企业:以场景需求为导向,分阶段落地技术
1.明确场景优先级,分步实施:优先选择高价值、低复杂度的场景(如智能质检、全渠道自助服务)落地语音识别技术,积累经验后再拓展至复杂场景(如多语言服务、情感化交互);例如,零售企业可先部署智能质检系统,降低人工成本,再逐步推进多语言服务以支持跨境业务。
2.重视数据建设与隐私合规:建立 “标注数据采集 – 隐私保护 – 模型训练” 的闭环数据体系,通过用户授权、隐私计算(如联邦学习)确保数据合规使用;针对行业特殊场景,构建专属标注数据集(如金融企业的客服录音、医疗企业的问诊语音),提升模型行业适配能力。
3.推动系统集成与能力复用:选择支持多终端、多系统对接的语音识别解决方案,确保与现有客服业务系统(工单、知识库、CRM)的无缝集成;构建企业级语音识别能力平台,实现技术能力在不同业务线(如客服、营销、运维)的复用,降低整体部署成本。
6.2.2.对技术提供商:聚焦核心痛点,强化场景化创新
1.突破场景化技术瓶颈:针对极端噪声、小众方言、行业特殊术语等核心痛点,加大研发投入,开发场景化解决方案(如极端噪声专用增强模型、方言联合预训练模型、行业术语词典优化工具);例如,针对政务客服的方言需求,开发 “多方言 + 政务术语” 专用模型,提升本地化服务能力。
2.降低技术部署门槛:推出轻量化、低代码的语音识别产品,支持边缘终端部署与快速系统集成;例如,提供 “API 接口 + 预置模板” 的解决方案,企业无需专业 AI 团队即可快速接入,降低技术使用门槛;同时,通过模型压缩、算力优化,降低企业的部署与运维成本。
3.加强跨技术融合创新:推动语音识别与大语言模型、多模态融合、隐私计算等技术的深度协同,开发 “语音 – 语义 – 服务” 端到端的智能客服解决方案;例如,推出 “LLM + 语音识别” 的多轮对话系统,提升上下文理解与自然交互能力,满足企业对人性化客服的需求。
6.2.3.对政策制定者:完善支撑体系,推动行业健康发展
1.构建数据共享与隐私保护机制:出台跨企业、跨行业的语音数据共享规范,建立 “公共数据池”(如地方方言数据、通用客服数据),支持低资源语音识别技术研发;同时,加强数据隐私监管,明确语音数据的采集、存储、使用标准,打击违法违规行为,保护用户权益。
2.加大技术研发与人才培养支持:设立专项基金,支持语音识别技术在极端场景、低资源场景、多模态融合等方向的研发;鼓励高校、科研机构与企业合作,培养 “语音识别 + 智能客服” 的复合型人才,解决行业人才短缺问题。
3.推动行业标准建设:制定智能客服语音识别技术的性能评估标准(如准确率、延迟、鲁棒性指标)、安全合规标准(如数据隐私、系统安全),规范行业发展;建立行业认证体系,对语音识别产品进行性能与合规性认证,帮助企业选择优质解决方案,避免 “劣币驱逐良币”。
7.未来展望
随着人工智能技术的持续演进,语音识别与智能客服的融合将朝着 “更精准、更高效、更自然、更普惠” 的方向发展:未来的智能客服将不再是 “机械的语音交互工具”,而是能够理解用户情感、精准匹配需求、提供个性化服务的 “数字化服务伙伴”;语音识别技术将作为这种 “伙伴关系” 的核心交互入口,与大语言模型、多模态融合、隐私计算等技术协同,推动智能客服从 “降本增效” 向 “价值创造” 升级,为企业数字化转型与用户体验优化提供更强有力的支撑。
参 考 文 献
[1] Pascual S, Bonafonte A, Serra J. SEGAN: Speech enhancement generative adversarial network[J]. Proc. Interspeech, 2017: 3642–3646.
[2] Tan K, Wang D. A convolutional recurrent network for real-time speech enhancement[J]. Proc. Interspeech, 2018: 3229–3233.
[3] Luo A, Mesgarani N. Conv-TasNet: Surpassing ideal time–frequency magnitude masking for speech separation[J]. IEEE/ACM Trans. Audio, Speech, Lang. Process., 2019, 27(8): 1256–1266.
[4] Kong Y, Wang Z, Watanabe S. Speech enhancement with score-based generative models[J]. Proc. ICASSP, 2023: 111–115.
[5] Chen H, Dong J, et al. CDiffuSE: Conditional diffusion model for speech enhancement[J]. IEEE/ACM Trans. Audio, Speech, Lang. Process., 2024, 32: 299–312.
[6] Chen Z, Luo Y, Yoshioka T. Continuous speech separation with conv-transformer TasNet[J]. Proc. ICASSP, 2020: 5746–5750.
[7] Chen Z, Luo Y, Yoshioka T. Conv-Transformer-TasNet for speech separation in multi-speaker environments[J]. Proc. ICASSP, 2020: 5746–5750.
[8] LIU H, GAO Z, ZHANG Y, et al. Mobile-Conv-TasNet: Lightweight speech enhancement for mobile intelligent customer service[J]. IEEE Access, 2023, 11: 48923-48932.
[9] Baevski A, Zhou Y, Mohamed A, et al. wav2vec 2.0: A framework for self-supervised learning of speech representations[J]. Advances in Neural Information Processing Systems, 2020, 33: 12449–12460.
[10] Babu A, Wang C, Tjandra A, et al. XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale[EB/OL]. 2021. arXiv:2111.09296.
[11] Hsu W-N, Bolte B, Tsai Y-H H, et al. Robust wav2vec 2.0: Analyzing Domain Shift in Self-Supervised Pre-Training[C]// Proc. INTERSPEECH. 2021: 1279-1283.
[12] An K, Li Z, Gao Z, Zhang S. Paraformer-v2: An Improved Non-Autoregressive Transformer for Noise-Robust Speech Recognition[EB/OL]. 2024. arXiv:2409.17746.
[13] Gao Z, Zhang S, Wu C, et al. Paraformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech Recognition[EB/OL]. 2022. arXiv:2206.08317.
[14] Guo Y, Zhang X, Zhang Y, et al. Wav2vec 2.0 Embeddings Generation for Paralinguistic Analysis and Two-stage Finetuning Strategy[C]// Proc. INTERSPEECH. 2023: 1863-1867.
[15] Vyas A, Madikeri S, Bourlard H. Comparing CTC and LF-MMI for Out-of-Domain Adaptation of wav2vec 2.0 Acoustic Model[C]// Proc. INTERSPEECH. 2021: 2861-2865. doi:10.21437/Interspeech.2021-1683.
[16] Zhang S, Wu C, Gao Z, et al. Streaming Paraformer: Multi-pass Alignment with CTC for Streaming Non-autoregessive ASR[EB/OL]. 2023. arXiv:2306.02244.
[17] Baltrušaitis T, Ahuja C, Morency L-P. Multimodal machine learning: A survey and taxonomy[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(2): 423-443.
[18] Zadeh A, Chen M, Poria S, et al. Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph[C]//Proc. ACL. 2018: 2236-2246.
[19] Tsai Y-H H, Bai S, Liang P P, et al. Multimodal Transformer for Unaligned Multimodal Language Sequences[C]//Proc. ACL. 2019: 6558-6569.
[20] Ngiam J, Khosla A, Kim M, et al. Multimodal deep learning[C]//Proc. ICML. 2011: 689-696.
[21] Srivastava N, Salakhutdinov R. Multimodal learning with deep Boltzmann machines[C]//Proc. NIPS. 2012: 2222-2230.
[22] Hori C, Hori T, Lee T Y, et al. Attention-based multimodal fusion for video description[C]//Proc. ICCV. 2017: 4193–4202.
[23] Kiela D, Bulat L, Nickel M, et al. Learning visually grounded sentence representations[C]//Proc. NAACL. 2018: 408-418.
[24] Kahn J, Lee A, Hannun A, et al. Self-training for end-to-end speech recognition[C]//Proc. ICASSP. 2020: 7084–7088.
[26] Radford A, Kim J W, Xu T, et al. Robust speech recognition via large-scale weak supervision[J]. arXiv preprint arXiv:2212.04356, 2022.
[27] Wang C, Wu A, Pino J, et al. Large-scale self-and semi-supervised learning for speech translation[J]. arXiv preprint arXiv:2104.06678, 2021..
[28] Chopra S, Mathur P, Sawhney R, et al. Meta-learning for low-resource speech emotion
作者:苏立伟来自中国南方电网有限责任公司用户生态运营公司

 京公网安备 11010502050959号
京公网安备 11010502050959号