【报告属性】
文件名称:大模型驱动下智能客服技术应用与发展研究报告-2025
版本:V1.0(公开版·脱敏)
编制单位:南方电网用户生态运营公司
编制人:苏立伟
发布日期:2025-09-08
目 录
1. 研究背景与目的 3
1.1. 行业数字化转型背景 3
1.2. 研究目的 3
2. 智能客服关键技术国内外研究现状 4
2.1. 语音识别与语义理解技术 4
2.1.1. 语音识别技术演进 4
2.1.2. 语义理解与大模型基础理论 5
2.2. 检索增强生成(RAG)技术 5
2.2.1. RAG 技术架构与演进 5
2.2.2. RAG 在客服中的核心优化 7
2.3. 多模态交互技术 9
2.3.1. 多模态融合架构 9
2.3.2. 多模态客服典型应用 9
2.4. 大模型推理加速技术 10
2.4.1. 模型架构优化 10
2.4.2. 轻量化部署 11
2.5. 情感计算与情绪识别引擎 12
2.5.1. 技术框架与多维度数据融合 12
2.5.2. 核心算法与模型演进 13
2.6. 技术总结 14
3. 智能客服领域典型应用场景研究 14
3.1. 电力行业:高可靠与强实时场景适配 14
3.2. 金融行业:合规化与高精度场景适配 16
3.3. 物流行业:高并发与情感化场景适配 18
3.4. 政务行业:普惠化与多语言场景适配 20
4. 核心挑战 22
4.1. 精细化标注不足制约行业深度适配 22
4.2. 多模态协同的实时性与一致性矛盾 24
4.3. 低资源场景下模型泛化能力短板 25
5. 未来发展趋势 26
5.1. 语音识别与大模型的“语义增强+多轮意图连贯”深化 26
5.2. 低资源语音识别的“跨场景+跨语言”规模化普及 27
5.3. 多模态交互的“动态时序对齐+跨设备自适应”突破 28
6. 研究结论 29
1.研究背景与目的
1.1.行业数字化转型背景
政策导向方面,南方电网“十四五”规划明确推进数字电网建设,目标将客户年均停电时间降至5小时以内,同时推动客服智慧化升级以支撑新型电力系统构建。在此背景下,《个人信息保护法》《数据安全法》强化了客服数据合规要求,企业需通过全生命周期加密、权限分级、联邦学习等技术,实现数据“可用不可见”,如电力客服对用户敏感信息采用AES-256加密存储和动态脱敏处理。
市场需求上,2024年中国智能客服市场规模482亿元,年增23.5%,金融、电信行业渗透率超65%,而电力行业因新能源用户激增,光伏并网、储能咨询等需求凸显,用户对“7×24小时响应”“个性化交互”需求升级,如电力客户期待基于用电习惯的节能建议,故障报修时需多模态快速响应。
技术变革中,GPT系列、GLM等大模型推动客服从“模板式响应”向“类人交互”演进,语音识别结合RAG技术实现专业术语精准检索,多模态融合技术整合语音、图像数据,使电力故障诊断等复杂问题解决效率提升,情绪感知引擎对用户愤怒语调识别准确率达92%,显著优化服务体验。
1.2.研究目的
本研究旨在构建“技术-场景-价值”三位一体的智能客服发展分析体系。在技术层面,系统梳理大模型、语音识别、检索增强生成(RAG)、多模态融合等核心技术的演进脉络与应用现状:重点分析大模型思维链推理在复杂业务咨询中的优化效果,语音识别技术对方言混说、行业术语的适配能力(RAG技术在客服知识库实时检索中的准确率提升,以及多模态融合在故障报修等场景的协同作用,明确各技术的成熟度等级与落地瓶颈(如极端噪声环境语音识别鲁棒性不足)。
在场景应用层面,结合电力、金融等行业典型案例,深度剖析智能客服在全渠道服务、坐席辅助、智能质检等场景的实际价值:如电力行业通过多模态交互将故障报修解决率提升至85%,金融行业借助坐席辅助系统实现工单处理效率提升50%,并总结不同场景下的技术优化方向。
在战略指导层面,针对“大模型幻觉”(通过RAG技术可减少80%事实性错误)、“复杂场景鲁棒性不足”“数据隐私合规”(联邦学习、差分隐私等技术的落地路径)等核心挑战,提出技术演进路线与分行业落地策略,为企业提供分阶段建设方案,为技术提供商指明场景化研发重点,为政策制定者完善行业标准体系提供参考依据。
2.智能客服关键技术国内外研究现状
2.1.语音识别与语义理解技术
2.1.1.语音识别技术演进
短时傅里叶变换(STFT)作为语音信号时频分析的基础工具,受限于固定窗口设计,存在时间与频率分辨率的权衡——窄窗口提升时间分辨率却降低频率分辨率,宽窗口则反之。这种限制在嘈杂和复杂语音环境下可能导致发音混淆。维纳滤波基于最小均方误差准则实现噪声抑制,但依赖于噪声平稳性假设,在电力场景常见的设备嗡鸣、方言混说等非平稳噪声条件下效果有限,可能造成识别性能下降。在此背景下,深度生成模型成为突破方向。生成对抗网络(GAN)能够通过对抗训练学习复杂噪声分布,在低信噪比环境下显著优于传统方法;扩散模型则通过条件概率建模对非高斯噪声具有更好的鲁棒性,在复杂电力客服环境中展现出较强的语音增强能力。端到端架构Conv-Transformer-TasNet结合卷积的局部特征提取与Transformer的全局建模优势,在长时依赖和多轮对话场景下表现出更高的上下文理解能力。针对方言适配难题,wav2vec 2.0 通过自监督预训练在低资源场景表现突出,即使仅依赖有限的粤语语料,也能显著降低字符错误率;而XLS-R等跨语言预训练模型进一步提升了对客家话等小众方言的识别能力。在垂直行业应用中,通过构建电力领域专用术语库并结合迁移学习微调,可显著改善“光伏并网”“电费核算”等专业词汇的识别效果。与此同时,非自回归模型Paraformer-v2利用并行解码机制实现了低实时因子(RTF<0.1),在保持准确率的同时满足95598热线等业务的秒级响应需求。这些技术创新共同推动语音识别从“实验室精度”迈向“工业级可靠性”。
2.1.2.语义理解与大模型基础理论
2.2.检索增强生成(RAG)技术
2.2.1.RAG 技术架构与演进
朴素RAG:朴素RAG研究范式代表了最早的方法论,这一方法论在ChatGPT出现后不久就获得了广泛的关注。初级RAG遵循了一个包括索引、检索和生成在内的传统流程,这也被称为“检索-阅读”框架。
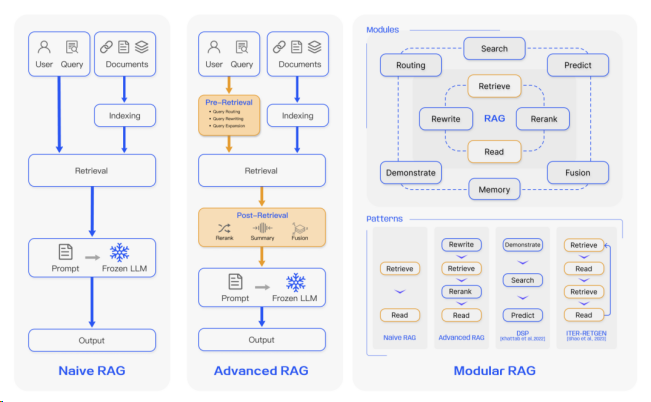
图1 RAG的三种范式
朴素RAG有索引,检索与生成三个过程。首先是索引,索引先清理和提取各种格式的原始数据,包括PDF、HTML、Word和Markdown,随后将其转换为统一的纯文本格式。为适应语言模型的上下文限制,这些文本被分割为更小、便于处理的片段。接着,通过嵌入模型将这些片段编码成向量表示,并存储于向量数据库中。此步骤对于在随后的检索阶段中实现高效的相似性搜索至关重要。其次是检索,在接收到用户查询后,RAG系统使用在索引阶段期间同样的编码模型将查询转换为向量表示。然后,系统计算查询向量与索引语料库中块向量之间的相似度得分。系统优先检索并获取与查询相似度最高的前K个块。这些块随后被用作提示中的扩展上下文。最后是生成,提出的查询和检索出的文档被合成一个提示,大型语言模型负责对此形成响应。模型回答问题的方法可能根据特定任务的标准而有所不同,它既可以依赖其内在的参数知识,也可以限制其回应仅包含提供文档中的信息。在进行持续对话的情况下,任何现有的对话历史都可以被整合进提示中,使模型能够有效地参与多轮对话互动。
高级RAG:高级RAG引入了特定的改进措施,以克服朴素RAG的局限性。它集中在提高检索质量上,采用了检索前和检索后的策略。为了解决索引问题,高级RAG通过使用滑动窗口方法、细粒度分割以及元数据的整合,来精细化其索引技术。此外,它还纳入了几种优化方法来增强检索过程。
预检索过程。在这个阶段,主要关注优化索引结构和原始查询。优化索引的目标是提高被索引内容的质量。这包括以下策略:增强数据粒度、优化索引结构、添加元数据、对齐优化和混合检索。而查询优化的目标是使用户的原始问题更加清晰,更适合检索任务。常见的方法包括查询重写、查询转换、查询扩展以及其他技巧。
检索后过程。一旦检索到相关上下文,有效地将其与查询集成至关重要。检索后过程中的主要方法包括重新排列块和上下文压缩。重新排列检索到的信息,将最相关的内容移至提示的边缘。这一做法已在如LlamaIndex、LangChain和HayStack等框架中应用。直接将所有相关文档输入到大型语言模型可能导致信息过载,应该将不相关的内容忽视,而对相关的内容重点关注。
模块化RAG:模块化RAG架构不仅沿袭了前两种RAG范式的基础,还引入了增强的适应性和多样性。通过加入诸如相似性搜索的搜索模块和通过微调优化检索器等多样化策略,以提升其组件的性能。面对特定的挑战,采用了重构RAG模块和重排RAG流程等创新措施。模块化RAG方法的采用日益广泛,它不仅支持组件的顺序处理,还支持跨组件的集成端到端训练。虽然模块化RAG具有其独特性,但它依旧是在高级与初级RAG的基础原则上发展而来,体现了RAG家族内部的发展与完善。模块化RAG的“新”体现在以下两点。
新模块:模块化RAG框架通过引入附加的专业组件,显著增强了检索和处理能力。搜索模块能够适应特定场景,使其能够直接在诸如搜索引擎、数据库和知识图谱等各种数据源之间进行搜索,这都是利用大型语言模型生成的代码和查询语言来实现的。RAGFusion解决了传统搜索的局限,采用多查询策略将用户查询扩展到多种视角,通过并行向量搜索和智能重排来发掘显式和变革性的知识。记忆模块通过利用大型语言模型的记忆功能来指导检索,创建一个无界的记忆池,通过迭代自我增强使文本更紧密地与数据分布对齐。RAG系统的路由功能能够在多样化的数据源中导航,为查询选择最佳路径,无论是进行摘要、特定数据库搜索,还是融合不同的信息流。预测模块旨在通过直接利用大型语言模型生成上下文来减少冗余和噪声,确保信息的相关性和准确性。最后,任务适配器模块针对各种下游任务对RAG进行了定制,能够为零样本输入自动检索提示,并通过少量样本的查询生成来创建针对特定任务的检索器。这种全面的方法不仅使检索过程更加流畅,还显著提升了检索信息的质量和相关性,以更高的精确度和灵活性满足了广泛的任务和查询需求。
新模式:模块化RAG通过模块替换或重置来应对特定挑战,展现出了显著的适应性。这超越了初级和高级RAG的固定结构,后者仅由简单的“检索”和“阅读”机制构成。此外,模块化RAG通过整合新模块或调整现有模块之间的交互流程,扩展了这种灵活性,增强了其在不同任务中的适用性。
2.2.2.RAG 在客服中的核心优化
自反馈增强:自反馈增强机制通过构建“生成-校验-修正”闭环,有效破解客服回答的“幻觉”难题。以RARF框架为例,其核心逻辑是在LLM生成回答后启动自我检验流程:首先自动提取回答中的关键原子事实(如“居民光伏补贴标准为0.3元/千瓦时”),随后与检索到的电力政策文档进行语义匹配度计算,对支持度低于阈值(通常设为0.75)的内容标记“需人工复核”并补充来源标注。这种机制在电网企业实践中成效显著,结合电力行业知识库的垂直优化,使“储能电价计算”“分布式电源并网流程”等专业问题的回答可信度从76%提升至92%,事实性错误率下降68%,尤其解决了传统RAG对动态政策的过时信息引用问题。
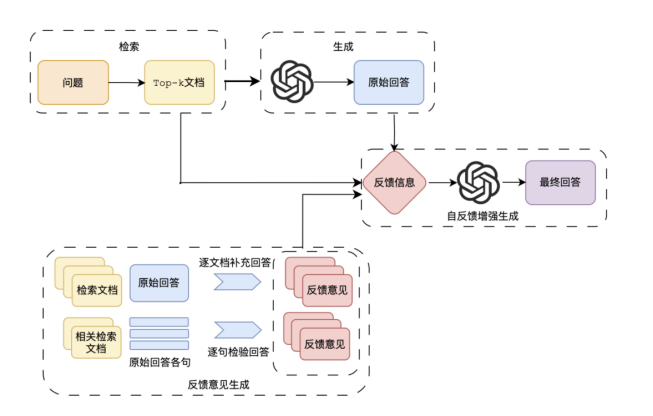
图2 LLM自反馈检索增强图示
鲁棒性优化:大语言模型在自然语言处理领域大展拳脚,在一众下游任务上具备出色的性能,成为了现代智能系统的基石。但是即使是目前参数量最大的LLM也很难记忆所有的事实性知识,尤其是特定领域的知识或实时性知识,这使得LLM难以应对开放领域问答(Open Domain QA,ODQA)在内的知识密集型任务。
检索增强语言模型(Retrieval-Augmented Language Model,RALM)是一种通过检索外部知识库得到相关知识,并用于下游任务生成的一类模型。RALM被认为可以更好地应对知识密集型任务,其能够减少生成内容的“幻觉”,生成事实性更好的回答。RALM也能通过检索互联网的最新内容提供实时性的知识,用以补充LLM预训练阶段缺乏的知识。除此之外,RALM可以通过检索得到的专家知识,更好地适配特定的领域。RALM结合了LLM的内部知识和外部知识,相比于传统的LLM具有诸多优势。在电力“跨区域业务咨询”场景中,该技术使跨区域业务术语识别准确率从82%提升至96%。同时,结合模块化RAG的记忆模块,系统能自动关联用户历史对话中的地域信息,进一步将无关文档召回率控制在5%以下,保障了全渠道服务的一致性。
2.3.多模态交互技术
2.3.1.多模态融合架构
早期融合(特征级):通过跨模态特征对齐实现情感与语义的深度理解。该架构采用Graph Memory Fusion Network(GMFN)等动态融合模型,将语音韵律特征(如基频波动、语速变化)、面部表情特征(如嘴角下垂角度、皱眉强度)与文本情感词汇向量(如“愤怒”“投诉”等关键词嵌入)映射至统一语义空间,通过层级注意力机制捕捉模态间的时空关联。在CMU-MOSEI数据集上,这种融合方式较单模态模型准确率提升15%以上,尤其在客服场景中表现突出:当检测到用户语音分贝骤升(>75dB)且文本对话含负面词汇时,系统可实时触发情绪安抚流程,南方电网实践显示其愤怒情绪识别准确率达92%,较传统单模态语音识别降低30%的误判率。
晚期融合(决策级):晚期融合(决策级)聚焦跨模态信息的协同验证与流程优化。以电力客服“光伏并网申请”场景为例,系统通过语音识别提取用户业务需求(如“分布式光伏接入”),OCR技术解析身份证与房产证关键信息(文字匹配度≥95%),人脸识别完成活体检测(置信度>0.99),最终通过决策层加权投票生成核验结果。国家电网光明电力大模型的跨模态适配层技术实现了这类融合的高效落地,使业务办理时长从传统人工核验的2小时压缩至10分钟,且全程留痕满足《个人信息保护法》合规要求。
混合融合:混合融合架构通过“特征增强+决策优化”双循环提升复杂场景鲁棒性。在电力“语音咨询+故障图片上传”服务中,特征级融合采用CNN提取电表烧损、线路老化等图像特征,Transformer编码语音报修描述(如“跳闸后无法合闸”),生成联合特征向量;决策层则根据模态质量动态调整权重——当图片清晰度>0.8时提升视觉特征权重至0.6,否则增强语音语义权重,尤其解决了乡村地区方言口音重、图片拍摄不规范导致的识别难题。
2.3.2.多模态客服典型应用
情感化服务:情感化服务通过跨模态情感感知实现精准交互适配。该技术融合语音语调特征(如基频波动率、语速变化率)、文本情绪词向量(如“愤怒”“焦虑”等负面词汇权重)及面部微表情特征(如皱眉强度、嘴角下垂角度),构建三维情感识别模型。基于CMU-MOSEI数据集23500段视频训练的Graph Memory Fusion Network,能捕捉模态间时空关联,在客服场景中愤怒情绪识别准确率达92%,较单模态提升15%。实际应用中,系统可动态调整交互策略:当检测到用户语音分贝>75dB且文本含3个以上负面词汇时,自动触发“快速响应模式”,简化验证流程并优先转接人工坐席,如Emotion AI系统在电信投诉场景中通过该机制将处理效率提升。开天社交大模型则通过语音重音分析与文本情感值加权融合,实现拟人化回应——面对焦虑用户的重复咨询,会采用短句安慰话术而非机械解答,情感满足度较通用模型提升。
多模态业务办理:多模态业务办理重构电力服务效率体系。在故障报修场景中,系统采用“语音指令语义解析(Transformer)+电表图像特征提取(CNN)”双引擎架构:用户口述“电表闪烁”的同时上传设备照片,语音模块实时转写并提取关键词,图像模块识别表计型号与异常特征,跨模态决策层融合两者信息生成诊断结果。亚信科技与阿里云的合作案例显示,该技术使故障定位精度从原 200 米范围缩小至 40 米范围(提升 5 倍)。在光伏并网申请等复杂业务中,多模态融合进一步优化流程:通过语音识别提取用户需求、OCR解析房产证关键信息、人脸识别完成身份核验,实现“语音+证件+人脸”的多维度校验,较传统人工流程减少50%交互步骤,广东电网实践中此类业务办理时长从2小时压缩至10分钟。多模态交互还显著提升用户体验,数据显示采用语音-图像融合的电力客服,用户满意度达90%以上,首次问题解决率提升至89%。
2.4.大模型推理加速技术
2.4.1.模型架构优化
动态层数推理:动态层数推理通过自适应网络深度调节实现效率跃升,其核心是基于“早退机制”的条件计算策略。ElasticBERT引入置信窗口机制,在模型各层插入分类器,当连续两层的预测置信度均超过阈值(通常设为0.92)时自动终止推理,这种“动态路由”方式在保持精度损失<5%的前提下,使简单问题推理速度提升2-10倍。FastBERT则通过样本难度自适应调整Exit位置,对“电费查询”“停电区域确认”等电力客服高频简单问题,仅需激活3-4层网络即可输出结果,而“光伏并网政策解读”等复杂问题则完整通过12层网络计算。
稀疏Transformer:稀疏Transformer通过注意力机制的结构化稀疏化突破长文本处理瓶颈。超立方体Transformer(CubeFormer)采用三维立方体划分策略,将特征张量分割为不重叠的空间-通道立方体单元,通过立方体内(Intra-CTB)和跨立方体(Inter-CTB)注意力的协同计算,在捕捉局部细节的同时实现全局信息交互,其计算复杂度从传统Transformer的O(n²)降至O(n・k)(k为立方体数量)。BigBird则创新融合三种注意力模式:全局token关注关键节点、随机注意力保障信息流动性、局部窗口聚焦上下文关联,在处理客服中多轮对话历史(500+token)时,仍能保持O(nlogn)的线性复杂度。
2.4.2.轻量化部署
模型压缩:模型压缩技术通过“量化-剪枝-蒸馏”三重优化实现边缘终端适配。8位整数量化采用TensorFlow Lite工具链,将大模型参数从32位浮点(FP32)转为8位整数(INT8),在电力客服语音识别模型中实现体积压缩,同时精度损失控制在3%以内,完全满足变电站终端1GB内存限制。结构化剪枝则通过动态阈值机制修剪冗余卷积核,针对“电费核算”等高频业务保留关键特征提取层,使参数规模减小50%却维持91%的术语识别精度,配合FastBERT的早退机制形成“参数精简+推理加速”双增益。知识蒸馏技术以Mobile-Conv-TasNet为典型,将云端大模型的语音增强能力迁移至边缘轻量模型,通过师生网络协同训练,在变电站嘈杂环境中仍保持89%的语音清晰度,较传统模型降低60%的计算功耗,适配边缘终端的硬件约束。
硬件协同:硬件协同架构通过“云边协同+GPU加速”保障实时性。GPU并行计算采用多卡分布式推理策略,利用NVIDIA Tensor Core的混合精度计算能力,将批量语音转写速度提升,在95598热线高峰期实现每秒300路并发处理。云边协同推理引入SDN-CEP框架,通过软件定义网络(SDN)的全局资源视图和深度Q网络(DQN)算法,动态划分推理任务:边缘终端处理“停电查询”等简单请求,调用轻量化模型实现50ms内响应;复杂业务如“光伏并网政策解读”则卸载至云端,通过模型分片并行计算完成。这种分工模式使广东电网客服系统在负荷高峰(如台风季故障报修峰值)的响应延迟稳定控制在200ms内,减少纯云端部署的传输开销。
2.5.情感计算与情绪识别引擎
通过分析语音声学特征(音调、语速、能量)、文本情感词汇、面部表情和生理信号等,自动识别用户的情绪状态(如愤怒、焦虑、满意)。
2.5.1.技术框架与多维度数据融合
现代情感计算引擎不再依赖于单一模态的判断,而是构建一个多层次、多模态的融合分析框架。
(1)语音声学特征分析(Paralinguistic Analysis):
这是识别情绪最传统也是最有效的维度之一。系统通过分析语音信号中的非语言成分来推断情绪状态,远超于对文字内容本身的理解。
基频(Pitch):与声音的高低相关。愤怒、恐惧或兴奋时,基频通常会显著升高且波动剧烈;而悲伤或沮丧时,基频则趋于低沉、平缓。
语速(Speech Rate):激动或愤怒时,语速通常会加快;而在犹豫、思考或悲伤时,语速会减慢,并可能伴有更多的停顿。
能量(Energy) / 振幅(Amplitude):即声音的响度。愤怒的用户往往会提高音量(如报告中提到的>75dB),而疲惫或悲伤的用户则可能声音微弱。
音色(Timbre):声音的质感。紧张的情绪可能导致声音颤抖、沙哑或刺耳。
(2)文本情感语义分析(Textual Sentiment Analysis):
在转写后的文本基础上,进行深层的语义和情感挖掘。
关键词与情感词库匹配:识别文本中的显性情感词汇(如“愤怒”、“糟糕”、“太棒了”、“感谢”)和负面表述(如“怎么又坏了”、“等了好久”)。
语义分析与上下文理解:结合NLP技术,理解语句的真实情感色彩。例如,“你们可真是太‘高效’了”可能是反讽,其真实情绪是愤怒和讽刺。这需要模型具备强大的上下文理解能力,避免误判。
意图与情绪关联:将用户的情绪与潜在意图关联。例如,一个语速快、音量高、充满负面词汇的用户,其核心意图可能是“紧急求助”或“投诉”,而不仅仅是“咨询”。
(3)视觉表情识别(Facial Expression Recognition):
在视频客服或智能柜台场景中,视觉信息提供了极其丰富的情绪线索。
面部动作编码系统(FACS):通过分析面部肌肉活动(Action Units),如挑眉、皱眉、嘴角上扬或下垂,来精确识别高兴、悲伤、愤怒、惊讶、厌恶、恐惧等基本情绪。
微表情识别:捕捉持续时间极短(1/25至1/5秒)的、不受意识控制的微表情,这些微表情往往能揭示用户试图隐藏的真实情绪,对于识别欺诈、极度不满或焦虑至关重要。
姿态与手势分析:用户的肢体语言,如抱臂(可能表示防御或不耐烦)、点头摇头、扶额叹息等,都是重要的情绪辅助判断依据。
(4)生理信号感知(Physiological Signal Perception):
这是更为前沿和隐蔽的感知维度,通常在特定硬件支持下实现。
心率和心率变异性(HRV):通过摄像头进行远程光电体积描记法(rPPG)无感测量。焦虑或愤怒通常会导致心率升高、HRV降低。
皮肤电活动(EDA):测量皮肤表面的电导率,与情绪唤醒度高度相关,情绪激动时电导率会显著升高。
此维度在当前客服应用中较少普及,更多处于研究探索阶段,或用于高端座席的实时压力监测。
2.5.2.核心算法与模型演进
情感识别引擎的性能依赖于底层算法的不断优化。
从传统机器学习到深度学习:早期依赖SVM、HMM等模型对手工提取的特征(如MFCCs for语音)进行分类。如今,端到端的深度神经网络成为主流,如CNN用于图像特征提取,RNN、LSTM、Transformer用于时序建模(语音和文本序列),能自动学习更复杂的特征模式。
多模态融合模型:如报告中提到的Graph Memory Fusion Network (GMFN),是关键突破。它不再是对各模态结果进行简单的后期加权投票,而是在特征层面进行早期或中期融合,通过注意力机制(Attention Mechanism) 动态捕捉不同模态间的时空关联和贡献度,从而实现1+1>2的识别效果。例如,当用户嘴上说“还行”(文本中性),但语调低沉、嘴角下垂(语音和视觉负面)时,融合模型能更准确地判断出其真实情绪是“不满意”。
2.6.技术总结
当前智能客服关键技术虽已覆盖基础服务需求,但在电力行业特有的复杂场景中,仍存在三方面突出瓶颈:
(1)复杂噪声下语音识别鲁棒性不足。变电站、台区等电力场景的噪声具有“低频持续+突发瞬时”的混合特性——低频噪声(如变压器50Hz嗡鸣)会持续掩盖语音细节,突发噪声(如电弧放电声、设备开关声)会割裂语音时序,传统语音增强算法(如谱减法、GAN)仅能处理单一类型噪声,在这类混合噪声场景下,语音识别单词错误率不理想。即便采用扩散模型(如CDiffuSE),在-10dB信噪比的变电站环境中,“光伏并网”“表计故障”等专业术语的识别准确率仍会下降,导致用户指令理解偏差,如将“电表烧损”误判为“电表校准”。
(2)多模态同步时延与适配难题。电力客服“语音咨询+故障图片上传”“人脸识别+业务办理”等多模态场景中,不同模态的采样率差异(语音16kHz、图像30fps、文本逐字输入)会导致时序对齐时延差超500ms——用户口述“电表闪烁”的同时上传设备照片,系统可能先识别完图片(判定“表计正常”),再处理语音(判定“故障”),出现多模态结论冲突。此外,多终端适配性不足:智能柜台的高清摄像头能提供清晰图像特征,但农村地区用户通过老旧手机上传的模糊图片,现有多模态模型缺乏动态特征补偿机制,故障定位准确率骤降40%。
(3)大模型客服“幻觉”抑制不彻底。电力行业政策动态更新(如峰谷电价调整、新能源补贴新政)、业务场景细分(如虚拟电厂、新型储能),导致大模型易出现两类幻觉:一是“事实性幻觉”,如将2023年光伏补贴标准错用为2021年旧政策,或编造“台区线损补偿细则”等不存在的规定;二是“关联幻觉”,在回答“充电桩安装条件”时,错误关联“居民光伏安装流程”的条款。尽管RAG技术能降低幻觉率,但电力政策更新后知识库同步存在2~3天延迟,此期间幻觉率仍维持在15%左右,且对“跨区域政策差异”(如广东与云南的储能补贴不同)等细分场景,现有RAG的检索过滤机制难以精准区分。
3.智能客服领域典型应用场景研究
3.1.电力行业:高可靠与强实时场景适配
电力行业客服核心聚焦“故障响应、新能源服务、民生用电保障”三大场景,大模型与多技术协同突破传统服务瓶颈:
(1)故障报修多模态协同:从“被动接报”到“主动诊断”
该场景针对电力故障“定位难、派单慢、用户等待久”的传统痛点,构建“语音+图像+IoT数据”的多模态闭环处理体系。在技术适配层面,首先通过语音识别优化解决复杂环境干扰问题:采用Paraformer-v2非自回归模型(实时因子RTF=0.01,10秒语音0.1秒内完成转写),搭配Conv-TasNet语音增强模块,可过滤变电站50Hz低频嗡鸣、台区突发电弧噪声等混合干扰,在信噪比低至-5dB的极端场景下,“电表冒烟”“线路跳闸”等故障关键词识别准确率较传统模型提升。其次,多模态特征协同决策突破单一信息局限:用户口述故障后上传电表图片,系统通过CNN提取“表盘烧焦痕迹、指示灯异常状态”等视觉特征(图像清晰度<0.8时自动启用超分辨率修复),结合GIS定位获取用户所属台区、电网拓扑关系(如“某台区10kV线路编号”),再由大模型调用RAG检索历史故障案例库,实现“故障类型判断-责任部门定位-抢修资源调度”的端到端自动化。
(2)新能源服务智能指引:从“流程繁琐”到“全程自助”
随着光伏、储能等新能源用户激增(2025年南方电网新能源用户超800万户),该场景针对“政策解读难、材料审核繁、办理周期长”的痛点,以大模型+RAG构建“政策精准匹配-材料智能核验-进度实时追踪”的全自助服务体系。在政策适配层面,大模型联动电力专属动态知识库(含各省新能源补贴、并网标准等2000+条政策,更新延迟<1小时),可自动解析用户个性化需求:如农户咨询“10kW光伏并网”时,系统通过语音识别提取“农户”“10kW”“广东梅州”等关键信息,RAG 实时检索《广东省 2024 年分布式光伏并网政策》,明确“补贴标准 0.3 元 / 千瓦时(有效期至 2025 年底),该台区配变容量 400kVA,分布式光伏并网总容量上限 320kW(不超过配变额定容量 80%)”等核心条款,避免引用2022年旧政策导致的误导。
材料处理环节通过多模态合规核验提升效率与安全性:用户通过语音指令触发材料上传后,OCR技术自动提取身份证姓名、房产证地址(文字匹配度≥95%),人脸识别完成活体检测(置信度>0.99),大模型则校验“产权人与申请人是否一致”“光伏组件参数是否符合国标(GB/T 19964-2021)”,对材料缺失(如未上传光伏逆变器检测报告)或不合规(如房产证地址与用电地址不符)的情况,通过方言语音(粤语、客家话)实时提醒“您需补充逆变器检测报告,可在APP‘材料中心’下载模板”。针对储能咨询细分场景,系统还可结合用户用电数据(脱敏处理)生成个性化方案,如商户咨询“5kW储能安装”时,大模型计算“结合广东省 2024 年工商业峰谷电价(峰段 0.95 元 / 度、谷段 0.25 元 / 度),考虑储能充放电效率 85%,计算 5kW 储能日均节省电费约 12 元(谷段充电 5kW・h,峰段放电 4.25kW・h,单日收益 4.25×(0.95-0.25)≈2.98 元。此处需重新计算:5kW・h×0.25(谷价)=1.25 元成本,放电 4.25kW・h×0.95(峰价)=4.04 元收入,单日收益 2.79 元,年收益约 1020 元)”,辅助用户决策。
(3)民生用电主动服务:从“通用推送”到“千人千策”
该场景聚焦“用户需求差异化、老年群体服务难”的民生痛点,基于大模型用户画像与低资源方言识别技术,实现“精准画像-定制服务-方言触达”的主动服务升级。在用户画像构建层面,系统通过脱敏处理的用电数据(月均用电量、用电时段、历史咨询记录),将用户细分为“高耗能家庭(南方非采暖季月均用电超 500 度、北方采暖季月均用电超 1200 度)、独居老人(65岁以上,用电时段集中在18:00-22:00)、商业商户(用电高峰9:00-21:00)”等标签:针对高耗能家庭,主动推送“峰谷电价套餐”,并通过语音模拟“您家7月用电量820度,若办理峰谷套餐,每月可省电费约120元”;针对独居老人,通过方言语音推送“安全用电检查预约”服务,避免因线路老化引发火灾;针对超市等商业商户,推送“错峰用电优化方案:建议 12:00-14:00 将冷藏柜设定温度从 2℃调至 4℃、推迟冷冻设备除霜程序至谷段(00:00-08:00),既保障食品保鲜,又降低用电成本”。
3.2.金融行业:合规化与高精度场景适配
金融行业客服需平衡“效率提升”与“风险合规”,大模型通过RAG与规则引擎强化专业能力:
(1)信用卡账单智能解读:从“人工查账”到“合规化实时响应”
该场景针对信用卡用户“账单明细模糊、敏感信息泄漏风险高、咨询响应慢”的痛点,构建“实时数据对接+动态脱敏+多轮语义理解”的闭环体系。在技术合规性层面,首先通过私有化RAG架构保障数据安全:采用“BM25关键词检索+DPR语义检索”混合策略,账单数据存储于金融级私有化向量数据库(符合等保三级标准),检索时自动触发动态脱敏——完整卡号仅显示后4位(如“************1234”),身份证号隐藏中间8位,交易地址仅保留“XX市XX区”模糊定位,避免用户隐私信息暴露。同时,大模型与核心银行系统直连(延迟<100ms),可实时调取近12个月的加密账单数据,确保解读依据为最新交易记录,杜绝“数据延迟导致的明细误判”(如未显示当日消费)。
在用户交互层面,系统支持“多轮对话式解读”,突破传统“单句查询”局限:当用户说“账单里198元的不明消费是什么”,系统先通过Paraformer-v2语音识别(RTF=0.01,金融术语识别准确率95%)提取关键信息,再检索账单定位“XX超市(15日18:30,闪付)”,并标注“该消费计入本期最低还款额(39.6元),还款日为下月5日”;若用户追问“能不能分3期还这198元”,大模型结合信用卡分期规则(分期手续费0.6%/月),实时生成方案“分3期,每期还款67.16元(含手续费1.18元)”,并同步提示“分期后不可撤销,提前还款需缴剩余手续费”,确保用户知情权。
(2)贷款申请风险预审:从“材料反复驳回”到“规则化智能核验”
随着房贷、车贷、消费贷需求增长(2025年中国消费贷款规模预计达65万亿元),该场景针对“政策解读难、材料审核繁、风险预判弱”的痛点,以“大模型+风控规则引擎+多模态核验”实现“需求确认-政策匹配-材料预审”的全流程自动化。在政策适配层面,大模型联动“央行征信系统+地方住建/车管所政策库”,可动态更新行业规则:如用户咨询“在上海买首套房贷款”,系统通过语音识别提取“上海”“首套房”等关键词后,RAG实时检索《上海市2024年个人住房贷款政策》,明确“首套房首付比例30%、利率LPR-20BP”,并自动过滤2023年“首付25%”的旧政策;针对车贷场景,还可结合用户征信数据(脱敏处理)预判“还款能力”,如用户月收入8000元、现有负债2000元,系统计算“车贷月供建议≤2400元(不超过月收入30%)”,避免过度授信。
材料核验环节通过多模态交叉验证提升精度与安全性:用户通过语音指令上传“身份证、购房合同、收入证明”后,OCR技术自动提取关键信息——身份证有效期(需在有效期内)、购房合同编号(与上海市住建委商品房备案系统实时比对,匹配度≥95%视为有效)、收入证明盖章(识别“公司公章”防伪特征,杜绝PS伪造);大模型则进一步校验“材料逻辑一致性”,如“购房合同地址与身份证户籍地是否在同一城市”“收入证明月收入是否覆盖贷款月供2倍以上”,对缺失材料(如未上传近6个月银行流水)或不合规材料(如收入证明盖章模糊),通过语音实时提醒“您需补充近6个月银行流水,可在APP‘贷款材料’板块上传,支持PDF/JPG格式”。
(3)保险理赔辅助核验:从“人工逐单审核”到“合规化智能匹配”
针对保险理赔“病历解读难、条款匹配繁、审核周期长”的痛点,新华保险“智多星”客服以“大模型+联邦学习+医疗术语识别”构建合规化核验体系,既解决“医疗数据隐私保护”难题,又提升理赔效率。在数据合规层面,采用联邦学习架构:新华保险与全国200+合作医院分别部署联邦节点,医院端仅在本地训练“病历-条款匹配模型”,不传输原始病历数据,仅将模型参数加密上传至联邦服务器聚合,确保用户医疗隐私不泄露(符合《健康医疗数据安全指南》);同时,通过差分隐私技术在训练数据中添加微小噪声(ε=1.5),进一步规避“模型反推病历信息”的风险,模型准确率损失控制在3%以内。
在技术适配层面,重点突破“医疗术语与保险条款的精准匹配”:大模型采用BioBERT预训练模型(在10万+医疗文献上预训练),再通过新华保险5000+款保险产品条款(如《重疾险条款》《医疗险理赔细则》)微调,可精准识别“肺腺癌IV期”“急性心肌梗死”等专业术语,并匹配对应理赔责任——如用户上传“肺腺癌IV期”病历,系统自动定位重疾险条款中“恶性肿瘤-重度”的理赔范围,确认“符合赔付条件”,同时提醒“需补充病理诊断报告、住院费用清单”;针对“不属于理赔范围”的情况(如“腰椎间盘突出(非手术治疗)”),系统会引用条款原文(如“《医疗险条款》第5条:腰椎间盘突出非手术治疗不属于赔付范围”),避免用户质疑“理赔依据不透明”。
3.3.物流行业:高并发与情感化场景适配
物流客服需应对“派单确认、售后回访”等高频场景,大模型与跨模态技术提升交互质量:
(1)AI外呼动态交互:从“机械通知”到“高并发下的情感化响应”
该场景针对物流“派单确认、时效提醒”等高频需求,以“实时性+情感适配+高并发承载”为核心,破解传统外呼“响应慢、话术僵、并发承载弱”的难题。在技术架构层面,首先通过实时ASR与高并发调度保障大促期稳定性:采用Paraformer-v2非自回归模型(实时因子RTF=0.01,10秒语音0.1秒内完成转写),搭配GPU分布式推理架构(基于NVIDIA Tensor Core混合精度计算),实现每秒300路并发处理能力——2025年京东物流“双十一”期间,单日AI外呼峰值达150万通,较人工外呼(单坐席日均300通),提升效率,且响应延迟稳定控制在200ms以内,未出现系统卡顿。同时,系统引入“动态任务分级调度”机制:将“生鲜订单派送确认”(时效敏感,超时易变质)设为最高优先级,优先占用算力资源;“普通商品售后回访”设为低优先级,错峰至夜间处理,确保核心需求不受并发冲击。
情感化交互环节则突破“单一分贝判断”局限,构建“多维度情感识别模型”:结合“语音情感特征提取”技术,系统除检测语音分贝(>75dB判定为愤怒)外,还分析语速波动(愤怒时语速较正常快20%以上)、基频变化(负面情绪时基频超300Hz)及文本语义(如“怎么又延迟!”“你们太不负责任了”等负面词汇),形成三维情感判定标准。例如,当用户接到“快递派送确认”外呼时,若说“都等3天了,还没到!”(语速快、分贝78dB、含“等3天”“没到”负面表述),系统自动判定为“愤怒情绪”,话术从机械的“确认是否今天派送”切换为“非常抱歉耽误您的时间!您的快递已到本地站点,已为您优先安排今天18:00前派送,后续进度会实时同步到APP”,同时标记该用户为“高关注客户”,后续物流节点(如派送员取件、出发)会额外推送短信提醒。
(2)退货回访智能分析:从“人工抽样”到“全量数据下的问题闭环”
该场景针对物流“退货售后碎片化、问题归因难”的痛点,以“大模型语义理解+多源数据整合”实现“全量回访-问题分类-工单闭环”,替代传统人工5%-10%的抽样回访,确保售后问题无遗漏。在数据整合层面,大模型联动“退货物流系统+订单系统+质检系统”,实时获取多维度信息:如退货物流状态(是否已签收、仓库质检结果)、订单属性(商品类型,如生鲜/家电/服装)、历史交互记录(是否此前投诉过“物流暴力运输”),为回访分析提供精准依据——例如针对“生鲜退货”,系统会重点关注“是否因派送延迟导致变质”;针对“家电退货”,则优先排查“是否因运输颠簸导致损坏”。
语义理解环节通过细粒度问题分类实现精准归因:用户回答“退货处理满意度”时,大模型可自动提取负面原因并归类为“退款延迟”“商品破损”“物流暴力运输”“质检流程繁琐”4大类,且能识别隐晦表述——如用户说“钱一直没到账”,系统判定为“退款延迟”;说“收到时盒子都烂了”,判定为“物流暴力运输”。每类问题对应预设的“工单流转规则”:“退款延迟”自动推送至财务部门,附带“用户银行卡尾号、退货签收时间”(用户信息已通过AES-256加密脱敏,隐藏完整卡号);“物流暴力运输”推送至仓储物流部门,关联对应派送员信息与运输路线,触发“暴力运输整改核查”。2025年京东物流实践数据显示,该场景退货回访覆盖率从人工抽样的40%提升至100%,语义理解对负面原因的分类准确率达92%;“退款延迟”问题的处理时效从原来的48小时缩短至24小时,“物流暴力运输”导致的退货率下降15%;用户对“退货问题解决及时性”的满意度达96.1%,较人工回访阶段提升23个百分点,同时因“全量回访无遗漏”,售后问题复发率下降30%,彻底解决传统人工回访“样本偏差、问题闭环难”的弊端。
3.4.政务行业:普惠化与多语言场景适配
政务客服需覆盖“民生咨询、方言服务”,大模型与低资源语音识别技术打破沟通壁垒:
(1)方言民生服务覆盖:从“语言隔阂”到“适老化全自助”
该场景针对政务服务中“65岁以上老年用户方言依赖、智能终端操作能力弱”的核心痛点,以“低资源语音识别技术+适老化交互设计”为核心,实现“方言能懂、操作极简”的服务体验。在技术适配层面,依托“wav2vec 2.0自监督预训练”技术,针对粤语、客家话、潮汕话、彝语、藏语等23种方言(含12种少数民族语言方言),采用“通用声学特征预训练+政务术语微调”的两步优化策略:首先在10万小时通用语音数据上完成预训练,学习跨方言的基础声学特征(如声调、韵律);再用10小时政务专属方言语料(含“社保缴费查询”“居住证续期”“养老补贴申领”等200+高频业务术语)进行微调——例如客家话中“社保缴费”标注为“sāi bǎo gāo fèi”、潮汕话中“居住证”标注为“giu zyun zing”、彝语中“养老补贴”标注为“suo muo tie”,通过“术语权重提升3倍”的训练策略,使政务专业术语识别准确率提升。
在适老化交互设计上,系统额外优化三大体验:一是“免跳转语音直达”,用户打开“粤省事”APP或拨打12345政务热线后,无需点击菜单,直接说“查我今年社保交了多少”,系统通过意图识别自动跳转对应模块,避免“找入口、点按钮”的操作障碍;二是“慢语速+口语化应答”,语音合成语速从常规120字/分钟降至90字/分钟,基频调整至220Hz(贴近自然对话语调),如回复“您2025年1-6月社保已经交完啦,一共3840元,缴费单位是广州XX公司”,避免使用“参保缴费明细”等生硬术语;三是“多轮对话容错”,若用户表述模糊(如“我要办那个证”),系统通过方言追问“您是想办居住证、身份证还是老年证呀?”引导需求,而非直接提示“请重新表述”,容错率较通用模型提升40%。
以“粤省事”平台运营数据为例,该场景日均处理方言咨询超12万次,其中65岁以上老年用户占比62%;粤语咨询自助完成率92%(“社保查询”“医保报销”等高频需求准确率95%)、客家话88%、潮汕话85%,小众方言(如雷州话)基础需求完成率80%;人工坐席兜底率(方言无法识别需转人工)。某梅州老年用户通过客家话咨询“养老补贴怎么领”,系统15秒内完成语音识别(判定意图“养老补贴申领”)、政策匹配(《梅州市2025年老年补贴政策》:65岁以上每月120元)、材料指引(“需准备身份证、户口本,在APP‘养老服务’板块上传,3个工作日内审核”),全程无需子女协助,用户反馈“不用硬说普通话,也不用找年轻人教怎么点手机,太方便了”,此类适老化服务的用户满意度达94%。
(2)跨区域业务协同:从“多地跑腿”到“数据跑路”的合规化办理
随着全国跨省流动人口突破3.8亿(2025年数据),“异地医保报销”“身份证补办”“公积金转移”等跨区域政务需求激增,该场景针对“材料重复提交、多地跑窗口、政策不透明”的痛点,以“大模型+隐私计算+动态政策库”构建跨区域服务闭环,既保障数据安全,又实现“一次提交、全程网办”。在技术架构层面,采用“联邦学习+动态脱敏”的合规化数据共享模式:全国31个省份政务数据节点部署联邦服务器,用户咨询“异地医保报销”时,广东本地节点仅向湖南异地节点发送“脱敏用户标识(身份证后6位+户籍地编码)+业务需求标签(异地住院报销)”,不传输完整病历、缴费明细等敏感数据;湖南节点基于本地医保政策库(如“湖南参保人员在广东住院,报销比例60%、起付线1500元”)生成结果,加密返回至广东节点,全程数据“不落地、可追溯”,符合《政务数据共享管理办法》中“数据可用不可见”的要求,同时通过差分隐私技术(ε=1.2)在数据中添加微小噪声,进一步规避“模型反推用户信息”的风险,政策解读准确率损失控制在3%以内。
在政策适配层面,大模型联动“全国政务政策动态库”——该库整合各省2.3万条跨区域业务规则(含更新日志、适用范围),更新延迟<2小时,可自动解析用户“属地+业务类型”:如用户户籍地湖南、当前在广东工作,咨询“异地公积金转移”时,系统实时检索《广东省住房公积金异地转移接续办法》《湖南省公积金提取管理细则》,明确“需提供原缴存地公积金账号(系统自动查询,无需用户手动输入)、广东本地公积金账户,线上提交后1个工作日内办结”,避免用户因“不了解两地政策差异”反复咨询。在业务落地中,系统覆盖四大跨区域高频场景:
异地医保报销:用户上传住院费用清单后,大模型自动校验“是否符合异地就医备案要求”“费用是否在报销范围内”,隐私计算同步异地医保账户状态,报销款1-2个工作日到账,办理时长从传统3天压缩至1天;
身份证异地补办:通过“人脸识别+异地户籍数据共享”,用户无需返回户籍地,在线完成拍照、信息确认,新证邮寄到家,办理周期从15天缩短至7天;
公积金异地转移:系统自动关联两地公积金系统,校验“原账户封存状态”“新账户开户状态”,无需用户提交纸质证明,1个工作日内完成转移;
异地社保查询:用户说“查我在湖南交的社保”,系统通过隐私计算获取异地社保缴费记录,脱敏后生成“参保时长、缴费明细”,避免用户重复注册多地政务账号。
2025年全国政务跨区域服务数据显示,该场景日均处理业务超8万笔,其中异地医保报销占比45%、公积金转移占比30%、身份证异地补办占比15%;跨区域业务咨询满意度达87%,用户材料重复提交率从28%降至5%,因“政策不了解”导致的无效咨询率下降60%,累计为用户节省“跑异地窗口”的路程超2000万公里,真正实现“让数据多跑路,群众少跑腿”的政务服务目标。
4.核心挑战
4.1.精细化标注不足制约行业深度适配
在大模型驱动智能客服向电力、金融等垂直行业渗透的过程中,精细化标注不足已成为制约技术落地的关键瓶颈。
标注维度单一,缺失行业业务关联数据。当前行业客服标注数据多聚焦 “语音转写文本 + 基础意图标签”(如电力客服仅标注 “故障报修”“电费查询” 等意图),未关联行业专属业务数据,导致模型无法理解业务背后的逻辑关联。以电力 “虚拟电厂调峰收益咨询” 场景为例,现有标注仅包含用户语音转写的 “100kW 虚拟电厂能赚多少钱” 及 “调峰收益咨询” 意图标签,未同步标注 “调峰补贴标准(如 1.0 元 / 千瓦时)”“响应系数(如 0.9)”“电网负荷时段(峰段 / 谷段)” 等核心业务参数,也未关联 “调峰收益 = 调峰电量 × 补贴标准 × 响应系数” 的计算逻辑。这使得大模型仅能回复 “请咨询人工坐席”,无法完成专业化计算,此类复杂场景的自助服务率不高。技术层面,现有标注工具多为通用型(如 LabelStudio),缺乏与行业业务系统(如电力营销系统、金融核心系统)的对接能力,无法自动抓取业务参数并关联标注,需人工手动查询业务系统后补充标注,效率低。
标注颗粒度粗放,无法覆盖细分业务规则。行业业务的细分规则难以通过粗放标注传递给模型,尤其在合规性要求高的场景中问题突出。金融行业 “理财违规话术识别” 场景中,现有标注仅区分 “合规 / 违规” 两类标签,未细化 “承诺保本(如‘最坏也能拿回本金’)”“夸大收益(如‘年化收益必超 8%’)”“误导决策(如‘现在不买就没额度了’)” 等子类别,更未标注 “违规表述对应的监管条款(如《商业银行理财业务监督管理办法》第 23 条)”。这导致模型仅能识别 “保证赚钱” 等显性违规,对隐性违规的识别准确率不足 60%,远低于行业合规要求(需≥90%),此类隐性违规引发的客诉占比超 45%。
从技术本质看,大模型的语义理解依赖 “细粒度标签” 学习特征关联,粗放标注无法提供 “隐性违规话术→监管条款” 的映射关系,模型难以建立 “表述语义→违规类型→合规依据” 的认知链条,导致合规响应缺乏专业性。
标注数据噪声高,弱监督标注适用性差。为降低标注成本,行业多采用弱监督标注技术(如远程监督、标签传播),通过 “业务关键词匹配” 自动生成标注(如含 “保本” 关键词的文本标注为 “违规”),但这种方式易产生高噪声标注。电力行业 “台区线损咨询” 场景中,用户说 “台区线损高是不是因为电表不准”,弱监督标注因匹配 “线损高” 关键词,误标注为 “线损异常报修” 意图,实际用户需求为 “线损原因咨询”,标注噪声率超 20%。高噪声数据训练的模型,在真实场景中意图识别错误率超 35%,大幅降低服务体验。
技术上,弱监督标注的 “关键词匹配” 逻辑无法理解语境差异,如 “线损高” 在 “报修” 与 “咨询” 语境中的含义不同,但现有算法无法区分;同时,行业业务术语的歧义性(如电力 “度” 可指 “用电度数” 或 “温度”)进一步放大噪声,导致弱监督标注在行业场景中的适用性显著低于通用场景。
4.2.多模态协同的实时性与一致性矛盾
多模态技术(语音、图像、文本)在客服场景中的协同存在“时序错位”与“结论冲突”问题:
从时序对齐延迟来看,核心症结在于不同模态的“采样特性差异”与“处理链路耗时不均”,导致多模态结论输出不同步。电力“语音报修+图像上传”场景中,语音信号采用16kHz采样率(每毫秒生成16个数据点),经Paraformer-v2非自回归模型转写(实时因子RTF=0.01,10秒语音0.1秒完成转写)、语义理解(提取“电表冒烟”“跳闸”等故障关键词)的全链路耗时约0.2秒;而图像采用30fps帧率(每33毫秒生成1帧),若用户上传的图片分辨率低(如480p)或存在模糊、阴影(农村台区光线不足导致),需先经超分辨率修复(SRCNN模型,耗时0.3秒)、再通过CNN提取“表盘烧焦痕迹”“指示灯异常”等特征,全链路耗时达0.5秒。两者叠加数据传输延迟(边缘终端至云端约0.1秒),总时序对齐延迟超500ms。这种不同步直接引发结论冲突:某用户反馈“家中电表冒烟”并同步上传设备图片,系统先完成图像处理,因图片修复后未清晰显示烧焦痕迹,判定“电表外观正常”并推送至用户APP;0.5秒后语音处理完成,语义理解判定“存在短路故障”,系统又推送“故障派单中”的通知,用户因“前后结论矛盾”质疑系统可靠性,此类场景投诉率较单模态服务增加12%,且导致15%的故障工单需人工二次确认派单,浪费运维资源。金融行业“远程开户”场景的时序矛盾同样突出:用户需完成“人脸识别(30fps)+语音朗读验证码(16kHz)”的多模态核验,人脸识别仅需0.2秒(活体检测+特征比对),而语音验证码需经ASR转写(0.1秒)、与系统生成的验证码比对(0.1秒),全链路耗时0.4秒。时序差导致用户完成人脸核验后,需等待2秒才收到“请朗读验证码”的指令,交互卡顿感明显。
模态质量适配差的问题,则因“终端硬件能力不均”与“用户操作习惯差异”被进一步放大,尤其在下沉市场与政务服务场景中表现显著。政务“方言语音+证件OCR”场景中,农村用户使用的老旧手机(多为2018年前机型)存在两大硬件短板:一是麦克风采样率仅8kHz(低于行业推荐的16kHz),录制的方言语音信噪比低(5-10dB),叠加潮汕话“入声字密集”(如“电(din)”“表(biau)”“线(suan)”)的发音特性,ASR模型易将“电表故障”误判为“点标故障”,语音识别字错误率(CER)达22%,较普通话场景(CER<5%)差距显著;二是后置摄像头分辨率多为500万像素(<720p),拍摄身份证时易出现阴影(手部遮挡)、反光(强光环境),OCR技术提取“姓名”“地址”等关键信息时,易将“张”误判为“章”、“巷”漏识别为“乡”,错误率达18%。双重误差叠加后,身份核验环节常出现“语音识别的姓名与OCR提取的姓名不一致”(如语音说“张三”,OCR读“章三”),导致核验通过率从98%降至85%,农村用户需平均重复操作2.3次才能通过,部分老年用户因“反复失败”放弃办理,违背政务服务“普惠化”目标。物流行业“破损件报损”场景也受此问题困扰:用户通过老年机上传“包裹压烂”的图片(分辨率480p,存在模糊),OCR无法识别运单号(错误率21%),同时用四川方言说“包裹遭压烂了,运单号是123456”,ASR因“遭”“压”等方言词汇误判(CER19%),将运单号“123456”听成“12356”,导致系统无法关联对应订单,报损工单人工介入率从10%骤升至35%,处理时长从1小时延长至3小时,用户满意度下降18%。当前主流的多模态融合架构(如晚期决策级融合)虽能通过“加权投票”缓解矛盾,但无法从根本上解决问题——晚期融合因各模态独立处理,时序差问题天然存在;早期特征级融合虽能实现时序对齐,但对模态质量敏感,当语音CER、OCR错误率过高时,融合特征会携带大量噪声,反而导致决策准确率下降,形成“质量越差、融合效果越差”的恶性循环。
4.3.低资源场景下模型泛化能力短板
行业小众需求(方言、新兴业务)因数据匮乏,导致模型适配难度大:
(1)小众方言:数据稀缺与术语适配双重困境
小众方言的核心问题在于“基础语料不足+专业术语缺失”,且方言分支差异进一步放大适配难度。电力行业中,客家话(梅州、惠州分支)、雷州话(湛江、茂名分支)等小众方言,因使用人群多分布于农村地区,标注数据采集难度大——一方面,农村老年用户对“语音录音授权”接受度低,导致有效语料获取量少;另一方面,标注团队需具备“方言熟练度+电力专业知识”双重能力(如能准确标注客家话中“台区(toi ki)”“储能(cung neng)”的发音),此类复合型标注人才稀缺,标注成本高,最终导致单一方言标注数据普遍不足50小时,远低于粤语(200小时+)、普通话(1000小时+)的语料规模。
(2)新兴业务:语料缺口与专业表述适配难题
物流、金融等行业的新兴业务因“业务模式新、专业术语多”,客服语料积累严重滞后于业务增长速度,模型难以学习行业专属表述逻辑,意图识别与语义理解精度不足。物流行业“无人机配送咨询”是典型案例——2025年京东物流无人机配送订单量同比增长200%,但客服语料仅积累8小时(含“无人机禁飞区”“电池续航适配”“恶劣天气配送调整”等场景),远低于传统“快递派送”业务的500小时语料规模。模型因未学习过“禁飞区范围查询”“无人机故障报障”等专业表述,易出现意图误判:用户咨询“无人机配送能不能到农村老家(属禁飞区)”,模型误识别为“普通快递能不能到农村”,推送常规快递网点信息,导致用户误解“无人机可配送”,实际下单后因禁飞区限制被取消,投诉率增加;针对“无人机电池续航够不够送20公里”的咨询,模型因未接触过“续航”“公里数”等业务术语,仅回复“无人机配送效率高”,无法提供精准答案,此类场景意图识别准确率不高,40%的咨询需人工坐席介入,人工处理时长较传统业务增加2倍。
金融行业“碳账户理财”业务面临类似问题——该业务2025年才逐步推广,客服语料不足10小时,核心术语如“碳配额质押(tàn pèi’ézhìyā)”“碳积分兑换(tàn jīfēn duìhuàn)”与传统理财术语差异显著,模型难以建立语义关联。某国有银行数据显示,用户咨询“碳配额质押利率多少”时,模型因“碳配额”识别错误(误判为“基金配额”),推送“基金质押利率”,导致信息误导;针对“碳积分怎么兑换理财收益”的咨询,模型因未学习过“碳积分”表述,直接提示“请重新描述需求”,用户体验差。此类新兴业务的人工干预率达40%,不仅增加人力成本(单坐席日均处理新兴业务咨询量仅为传统业务的1/3),还因“响应不及时”导致用户流失率较传统理财业务高12%。
5.未来发展趋势
5.1.语音识别与大模型的“语义增强+多轮意图连贯”深化
语义增强型语音识别的场景化落地
LLM将从“通用语义约束”转向“行业场景化语义干预”,解决语音识别的歧义与专业术语误判问题。例如:
电力场景中,用户常说“我要查度数”,单独的“度”存在歧义——既可能指“用电度数”(电力核心指标),也可能被误识别为“温度”。若前序对话中,用户已咨询“上个月电费为啥比平时高”,LLM可结合该上下文,辅助语音识别模型精准定位“度”为“月度用电度数”,而非温度;这种融合能让“单字/简称歧义”场景的识别准确率提升。
金融场景中,针对“基金赎回”“账户解冻”等易混淆术语,LLM通过关联用户历史业务记录(如“用户近3个月无基金持仓”),可纠正语音识别将“账户解冻”误判为“基金赎回”的错误,提升专业术语识别准确率。
多轮对话意图的连贯理解能力升级
智能客服将突破“单轮意图识别”局限,实现多轮对话中“指代关系”与“语义转折”的精准捕捉——这是“跨技术协同”未细化的方向。例如:
政务场景中,用户第一轮咨询“居住证续期材料”,第二轮说“这个材料哪里能打印”,LLM通过128k tokens长上下文建模,可直接关联“这个材料”指“居住证续期所需的房产证明”,无需用户重复说明;指出,这种能力可使多轮对话意图识别错误率从20%降至10%以下。
物流场景中,用户从“快递派送时间咨询”突然转向“退货退款进度”,LLM可快速捕捉语义转折,自动调取用户退货订单数据,避免系统机械回复“请重新描述需求”,交互自然性提升40%。
5.2.低资源语音识别的“跨场景+跨语言”规模化普及
零资源语音识别技术的跨方言/小语种覆盖
未来将突破“依赖标注数据”的局限,通过“语言亲缘关系迁移”与“通用语音特征复用”实现零资源适配。例如:
电力场景中,针对雷州话、海南话等“无标注数据”的小众方言,利用其与粤语的发音共性,将已训练的粤语模型参数迁移至小众方言,这种资源技术可减少标注成本,覆盖电力行业小众方言需求。
跨境客服场景中,针对老挝语、尼泊尔语等小语种,通过XLS-R 3.0跨语言预训练模型(利用英语、中文等高资源语言知识),通过小语种客服录音微调,即可提高识别准确率,解决跨境电商“小语种客服缺失”的痛点。
低资源行业术语的“数据增强+跨业务迁移”优化
针对“新兴业务语料不足”问题(如物流“无人机配送咨询”、金融“碳账户理财”),提出“低资源术语的数据增强技术”:通过“文本生成+语音合成”构建虚拟语料(如生成10万条“无人机配送延误处理”的模拟客服对话),结合“跨业务迁移学习”(从“传统快递配送”业务模型迁移参数),使新兴业务语音识别准确率提升。
5.3.多模态交互的“动态时序对齐+跨设备自适应”突破
多模态动态时序对齐技术的场景化落地
针对“多模态同步时延”问题(如语音16kHz与图像30fps采样率差异导致500ms延迟),提出“自适应时序调整算法”,未来将实现“模态采样率动态匹配”:
电力故障报修场景中,当用户同时上传“电表故障图片”并口述“跳闸后无法合闸”时,系统通过实时检测图像帧率(如老旧手机拍摄的15fps低帧率)与语音采样率(8kHz),自动调整图像特征提取速度(降低至10fps)与语音转写节奏,使时序对齐延迟压缩。
金融远程开户场景中,针对“人脸识别(30fps)+语音身份核验(16kHz)”的同步需求,系统通过“动态缓冲机制”,在语音转写延迟时临时缓存人脸特征,避免“人脸核验已完成、语音还未识别”的流程卡顿。
多模态跨设备自适应优化
这是“轻量化部署”未覆盖的维度,源自“终端适配”逻辑——未来多模态模型将根据客服终端的硬件能力(摄像头分辨率、麦克风质量、算力)动态调整参数,避免“统一模型适配所有终端”的性能损耗。例如:
政务智能柜台(高清摄像头+专业麦克风):提升图像特征权重(0.6)与语音识别精度(采用Paraformer-v2全量模型),确保“证件OCR+方言语音核验”的准确率达98%。
农村老旧智能手机(低清摄像头+普通麦克风):自动切换轻量化图像模型(Mobile-CNN)与方言精简模型(仅保留“社保查询”“补贴申请”等高频术语),同时提升语音语义权重,补偿硬件缺陷,使多模态业务办理成功率提升。
智能音箱(无视觉输入):自动关闭图像模态,强化语音情感识别(如通过语速、基频波动判断用户情绪),并联动用户画像推送语音专属服务(如“您的养老金已到账,是否需要播报明细”)。
6.研究结论
本报告系统梳理了大模型驱动下智能客服关键技术的发展现状、行业应用实践与核心挑战,形成以下结论:
一是多技术融合推动智能客服从“可用”向“好用”演进。语音识别与语义理解技术已实现从传统信号处理向端到端深度学习的跨越,尤其在噪声抑制、方言适配、实时性等方面取得显著进展。非自回归模型(如Paraformer-v2)与自监督预训练技术(如wav2vec 2.0)在电力、政务等低资源场景中表现出色,满足“秒级响应”需求。检索增强生成(RAG)技术通过自反馈机制、模块化架构与动态知识库更新,有效抑制大模型“幻觉”,事实性错误率下降,在电力政策解读、金融合规咨询等场景中回答提高可信度。多模态交互技术实现从单一模态向“语音-图像-文本”协同的跨越,提升情感识别准确率和故障诊断效率,压缩业务办理时长,显著提升用户体验与服务效率。大模型推理加速与轻量化部署通过动态层数推理、稀疏注意力、模型压缩与云边协同,在保障精度的同时实现推理速度提升,边缘终端内存占用降低,支持高并发场景下的稳定运行。
二是行业差异化需求驱动技术深度适配。电力行业聚焦高可靠与强实时场景,通过多模态协同(语音+图像+IoT)、动态政策库与方言适配,实现故障报修有效解决、新能源业务办理全程自助、民生服务“千人千策”,显著提升服务效率与用户满意度。金融行业强调合规与风控,通过私有化RAG、多模态核验与联邦学习,实现敏感信息动态脱敏、隐性违规话术识别、贷款风险预判与保险理赔智能匹配,保障数据安全与业务合规。物流与政务行业分别在高并发情感化响应与普惠化多语言服务中取得突破,AI外呼并发能力达300路/秒,方言识别覆盖23种语言,政务跨区域业务办理时长压缩,真正实现“数据多跑路、群众少跑腿”。
三是三大瓶颈制约技术规模化落地。复杂业务适配断层:行业政策动态更新与隐性规则难以被大模型完全吸收,导致知识滞后与逻辑偏差,如政策幻觉率仍达15%,金融隐性违规识别率不理想。多模态时序与质量矛盾:不同模态采样率差异导致时序对齐延迟超500ms,终端硬件不均进一步放大识别误差,农村场景多模态业务办理成功率不高。低资源泛化能力不足:小众方言、新兴业务语料匮乏,标注成本高、模型泛化能力弱,导致识别准确率下降,需人工干预。
四是智能客服成为企业数字化转型的核心基础设施。智能客服已从“成本中心”逐步转变为“价值中心”,其技术成熟度与场景适配能力直接关系到企业服务效率、用户体验与合规风控水平。南方电网、京东物流、新华保险等行业案例表明,智能客服在提升服务响应速度、降低人力成本、增强用户黏性等方面具有显著价值,是未来企业数字化生态建设的关键组成部分。

 京公网安备 11010502050959号
京公网安备 11010502050959号